Atlas:CCRC08May
Sommaire
T0-T1 transfer tests (week1)
T1-T1 transfer tests (week2)
Some summaries presented at ADC Operations Meeting http://indico.cern.ch/conferenceDisplay.py?confId=33976
T0-T1-T2 transfer tests (week3)
General remarks
https://twiki.cern.ch/twiki/bin/view/Atlas/DDMOperationsGroup#CCRC08_2_May_2008
The T0 load generator will run at "peak" rate for 3 days ("peak" rate means data from 24h/day of detector data taking at 200Hz are distributed in 24h, while "nominal" rate means data from 14 hours/day of detector data taking at 200Hz are distributed in 24h).
At peak rate 17,280,000 events/day are produced, corresponding to 27.6 TB/day of RAW, 17.3 TB/day of ESD and 3.5 TB/day of AOD (considering the sizes of 1.6 MB/event for RAW, 1.0 MB/event for ESD and 0.2 MB/event for AOD)
- monitoring page
data replication from CERN to Tier-1s http://panda.atlascomp.org/?mode=listFunctionalTests
data replication within clouds http://panda.atlascomp.org/?mode=listFunctionalTests&testType=T1toT2s
- Summaries / Reports
ADC Oper 22 May http://indico.cern.ch/materialDisplay.py?contribId=3&materialId=slides&confId=34556
T0-T1(LYON)
Shipping continuously data to T1s according to computing model, sites should demonstrate to sustain for 3 days the following export rates
| SITE | TAPE | DISK | TOTAL |
| IN2P3 | 48.00 MB/s | 100.00 MB/s | 148.00 MB/s |
Metric for success: Sites should be capable of sustaining 90% of the mentioned rates (for both disk and tape) for at least 2 days of test. For sites who would like to test higher throughput, we can oversubscribe (both to disk and tape).
As a reminder, here the table of the necessary space needed at each T1
| SITE | TAPE | DISK |
| IN2P3 | 12.4416 TB | 25.92 TB |
replication status is checked ~ every 2h http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests
T1-T2
T2s will receive AODs, which should be generated at a rate of 3.5TB/day. The amount that each site receives depends on the share
- IN2P3-LAPP_DATADISK : 12%
- IN2P3-CPPM_DATADISK : 5%
- IN2P3-LPSC_DATADISK : 5 %
- IN2P3-LPC_DATADISK : 13%
- GRIF-LAL_DATADISK : 30% (grid.admin a lal.in2p3.fr)
- GRIF-LPNHE_DATADISK : 15%
- GRIF-SACLAY_DATADISK : 20 %
- BEIJING-LCG2_DATADISK : 20 % (yanxf a ihep.ac.cn, Erming.Pei a cern.ch)
- RO-07-NIPNE_DATADISK : 10% (ciubancan a nipne.ro)
- RO-02-NIPNE_DATADISK : 10% (tpreda a nipne.ro)
- TOKYO-LCG2_DATADISK : 50% (lcg-admin a icepp.s.u-tokyo.ac.jp)
as written in https://twiki.cern.ch/twiki/bin/view/Atlas/DDMOperationsGroup#CCRC08_2_May_2008
The shares are decided rather arbitrary according to the free space in ATLASDATADISK. These numers can be raised at a later stage of the test, but at first we would like to be sure everythinig goes well with this rate.
The shares were increased around 2008-05-24 00:00 (CET)
* IN2P3-LAPP_DATADISK : 25% * IN2P3-CPPM_DATADISK : 5% * IN2P3-LPSC_DATADISK : 5 % * IN2P3-LPC_DATADISK : 25% * BEIJING-LCG2_DATADISK : 20 % * RO-07-NIPNE_DATADISK : 10% * RO-02-NIPNE_DATADISK : 10% * GRIF-LAL_DATADISK : 45% * GRIF-LPNHE_DATADISK : 25% * GRIF-SACLAY_DATADISK : 30 % * TOKYO-LCG2_DATADISK : 100%
Datasets are subscribed from parent Tier-1s ~ every 4h
replication status is checked ~ every 2h http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT2s
Lyon FTS monitor: http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsmonitor.php?vo=atlas
Current Status
T0-T1 (ALL) http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site
- Throughput
- Errors
- http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/OVERVIEW.num_file_xs_error.14400.png
T0-T1 (Lyon) http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site?statsInterval=4&name=LYON
- Throughput
- http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/LYON.throughput.14400.png
- http://dashb-atlas-data.cern.ch/dashboard/templates/plots/LYON.T1.throughput.14400.png
- Errors
- http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/LYON.num_file_xs_error.14400.png
- http://dashb-atlas-data.cern.ch/dashboard/templates/plots/LYON.T1.num_file_xs_error.14400.png
T1-T2 (Lyon) http://dashb-atlas-data.cern.ch/dashboard/request.py/site?statsInterval=4&name=LYON
- Throughput
- Errors
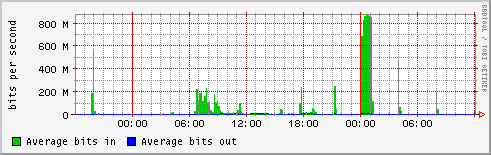
IN2P3 Weathermap
Logbook
24 May
- 24 May 14h00
Since 11h10-20, T0 exports are resumed, still with some errors but much less. the overall rate (T0-T1 but to Lyon) went over 1000MB/s, and sustained >900MB/s untill 12h10. then started decreasing. likely T0 load generation has stopped.
- 24 May 07h30
apparently, srm.cern.ch is down since 2008-05-24 06:56:26 (dashb). GGUS-Ticket 36761 has been created.
[FTS] FTS State [Failed] FTS Retries [1] Reason [SOURCE error during PREPARATION phase: [GENERAL_FAILURE] Error caught in srm::getSrmUser.Error creating statement, Oracle code: 18ORA-00018: maximum number of sessions exceeded] Source Host [srm-atlas.cern.ch]
In fact, it may not be down, but just too busy with too many accesses. Seems to have recovered 07h50. But down again? 08h30.
- Throughput
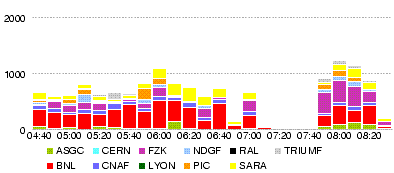
- Errors


- 24 May 00h14
Stephane noticed the new shares had been applied. It seems the subscriptions are made taking all the ccrc08_run2 data into account, not only from now on. That is, we will get much more data and rate than is expected from the shares.
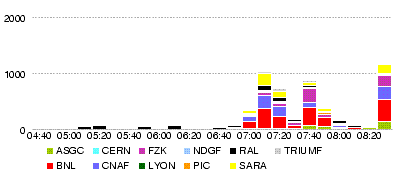
- Throughput

- Errors


Most of the errors are for IN2P3-CC_DATADISK (305: can't see the cause on dashb), IN2P3-CC_DATATAPE (168: can't see the cause on dashb), IN2P3-CC_MCDISK (80: source error at bnl), RO-02-NIPNE_DATADISK (33: TRANSFER_TIMEOUT, PERMISSION)
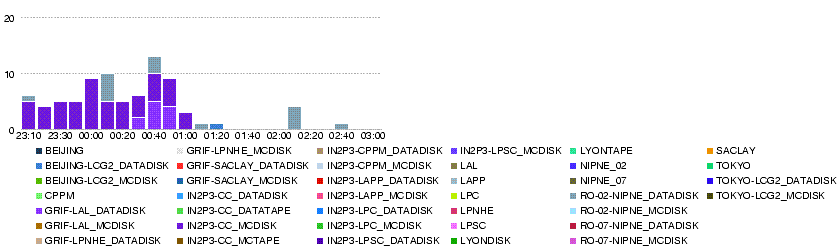
- LPC

23 May
- Throughput

- Errors

- 23 May 20h00
many failures to IN2P3-CC_MCDISK. with
Source Host [dcsrm.usatlas.bnl.gov].
now that T0-LYON transfers are also on production dashb, such errors are not nice in monitoring the ccrc transfers. GGUS-Ticket 36755 has been created.
- 23 May 08h20
Beijing has started working since 01:44, although with a number of errors until 07:43.
[FTS] FTS State [Failed] FTS Retries [1] Reason [TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out] Source Host [ccsrm.in2p3.fr]
after the last error at 07:43, transfers seem going well.
RO-02-NIPNE_DATADISK also working from time to time. still with many errors
22 May
- Throughput

- Errors

- There was a network problem for Romanian national Internet provider RoEdu from 6:30 to 10 GMT, according to Titi and Mihai.
- 22 May 22h50
Transfers to RO-02-NIPNE_DATADISK have been failing. GGUS-Ticket 36728 has been created.
Otherwise, transfers are going well except for BEIJING.
- 22 May 14h50
One file assigned to CPPM has a source problem;
Received error message: SOURCE error during PREPARATION phase: [REQUEST_TIMEOUT] failed to prepare source file in 180 seconds
with srm://marsedpm.in2p3.fr:8446/srm/managerv2?SFN=/dpm/in2p3.fr/home/atlas/atlasdatadisk/ccrc08_run2/AOD/ccrc08_run2.016765.physics_C.merge.AOD.o0_r0_t0/ccrc08_run2.016765.physics_C.merge.AOD.o0_r0_t0._0001__DQ2-1211460721
GGUS-Ticket 36709 has been created. https://gus.fzk.de/pages/ticket_details.php?ticket=36709
- 22 May 14h20
the T0->LYON export was migrated from T0 VOBOX to LYON VOBOX. Transfers T0->LYON should be monitored with the Production dashboard http://dashb-atlas-data.cern.ch/dashboard/request.py/site?name=LYON
- 22 May 13h05
Titi: Unfortunately there was an unscheduled network breakdown in our institute started from about 6:30 to 10 GMT.
- 22 May 12h40
Stephane switched back the certificate from Kors' certificate to Mario's.
- 22 May 10h29
starting 09:21:35, there are errors in transfers to RO-07-NIPNE_DATADISK in dashb.
[FTS] FTS State [Failed] FTS Retries [1] Reason [DESTINATION error during PREPARATION phase: [CONNECTION] failed to contact on remote SRM [httpg://tbit00.nipne.ro:8446/srm/managerv2]. Givin' up after 3 tries] Source Host [ccsrm.in2p3.fr]
GGUS-Ticket 36698 created
24 May 2008 11:35, Mihai: Sorry for this problem.But this was happening because of a problem occurred to our national Internet provider RoEdu.
- 22 May 09h40
According to Alexei, cron job for subscription to T2s does not run frequently during the night. That is why.
- 22 May 09h00
transfers T1-T2 resumed since 8h30. reaching 900MB/s in total.
numbers of assigned datasets to sites look better now.
Killed a MC data subscription to RO-07-NIPNE_MCDISK.
- 22 May 08h00
T0-T1 transfers are proceeding, No T1-T2 transfers to DATADISK since last night.
according to dq2.log, new subscriptions today (since 5.22 00:00) are queued only to BEIJING and RO-02-NIPNE, resulting in errors.
the status table does not look nice, I will check. http://panda.atlascomp.org/?mode=listFunctionalTests&testType=T1toT2s#LYON
apparently, no subscription to LAPP, CPPM, LPSC. TOKYO and LAL, who are assigned larger shares, have less subscriptions.
21 May
- Throughput all T0-T1

- Throughtput T0-LYON

- Throughput LYON-T2

- 21 May 23h30
There are many errors in transfers to NIPNE02
DESTINATION error during PREPARATION phase: [PERMISSION]
- 21 May 22h30
Stephane found a temporary solution for the LFC problem. It does not accept Mario's certificate, but does Kors' (thus no problem in T0-T1 transfers).
- 1 file ccrc08_run2.016730.physics_E.merge.AOD.o0_r0_t0._0001 to BEIJING done. http://dashb-atlas-data.cern.ch/dashboard/request.py/file-placement?site=BEIJING-LCG2_DATADISK&guid=45e816b9-82aa-434c-99f7-eb2ff3f7f9c9
- 9 datasets transferred to LPNHE http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=GRIF-LPNHE_DATADISK
- 9 datasets transferred to Saclay http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=GRIF-SACLAY_DATADISK
- no transfers to CPPM
- no transfers to LAPP
- 1 dataset ccrc08_run2.016733.physics_E.merge.AOD.o0_r0_t0 completed to LPC http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=IN2P3-LPC_DATADISK
- 2 datasets to RO-02-NIPNE_DATADISK in queue http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=RO-02-NIPNE_DATADISK
- 6 datasets to RO-07-NIPNE_DATADISK completed http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=RO-07-NIPNE_DATADISK
- no transfer to Tokyo after the very first one http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=TOKYO-LCG2_DATADISK
the dashb graphs show these transfers as of 19:xx (transfers done at 19:xx = 17:xx UTC, and registration done at around 22:30)
- 21 May 20h20
dashb shows transfers, which seem to be successful but with many registration errors, in the table (not in the graph). Looking into the details, file states are 'ATTEMPT_DONE' with 'HOLD_FAILED_REGISTRATION'

- 1 file ccrc08_run2.016730.physics_E.merge.AOD.o0_r0_t0._0001 has been transferred to BEIJING at 17:40:07 (submit time 17:34:04), all the other transfers failed with
globus_gass_copy_register_url_to_url: Connection timed out
http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=1beaf3f7-275c-11dd-a6af-d4b2876399e2 - 15 files transferred to IRFU at 17:35-17:46 (submit time 17:34:59) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=3c5f360b-275c-11dd-a6af-d4b2876399e2
- 2 files transferred to IRFU at 17:33 (submit time 17:32:56) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=f2d33d11-275b-11dd-a6af-d4b2876399e2
- 1 file ccrc08_run2.016733.physics_E.merge.AOD.o0_r0_t0._0001 has been transferred to IN2P3-LPC at 17:33 (submit time 17:32) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=f41f6c22-275b-11dd-a6af-d4b2876399e2
- 2 files transferred to IN2P3-LPNHE at 17:33 (submit time 17:32) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=f28bfae0-275b-11dd-a6af-d4b2876399e2
- 17 files transferred to IN2P3-LPNHE at 17:35-17:41 (submit time 17:34)
- all transfers to RO-02-NIPNE ATLASDATADISK are failing
TRANSFER error during TRANSFER phase: [PERMISSION] the server sent an error response: 550 550 rfio write failure: Permission denied.
TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out
TRANSFER error during TRANSFER phase: [GRIDFTP] the server sent an error response: 426 426 Transfer aborted (Unexpected Exception : java.io.IOException: Broken pipe)
DESTINATION error during PREPARATION phase: [PERMISSION]
http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftschannel.php?channel=IN2P3-NIPNE02&vo=atlas - 10 files transferred to NIPNE07 at 17:44-18:02 (submit time 17:35) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=53b15d6f-275c-11dd-a6af-d4b2876399e2
- 2 files transferred to NIPNE07 at 17:33 (submit time 17:33) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=0bb83976-275c-11dd-a6af-d4b2876399e2
- 3 files transferred to TOKYO at 13:00 (submit time 13:00) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=eae79bb0-2735-11dd-a6af-d4b2876399e2
the time on ftsmonitor is UTC.
- 21 May 19h30
Finally 19 more subscriptions appeared in the dq2.log.
- ccrc08_run2.016731.physics_D.merge.AOD.o0_r0_t0 (2 files) to BEIJING-LCG2_DATADISK and GRIF-SACLAY_DATADISK
- ccrc08_run2.016730.physics_B.merge.AOD.o0_r0_t0 (2 files) to BEIJING-LCG2_DATADISK and GRIF-SACLAY_DATADISK
- ccrc08_run2.016730.physics_D.merge.AOD.o0_r0_t0 (2 files) to BEIJING-LCG2_DATADISK and GRIF-SACLAY_DATADISK
and so on.
In the dq2.log, the files got FileTransferring, VALIDATED, FileCopied, but then, there are errors
FileTransferErrorMessage : reason = [FTS] FTS State [Failed] FTS Retries [1] Reason [TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_gass_copy_register_url_to_url: Connection timed out] FileRegisterErrorMessage : reason = LFC exception [Cannot connect to LFC [lfc://lfc-prod.in2p3.fr:/grid/atlas]]
- 21 May 18h20
Around 17h30 transfers resumed. Rate for 17h40-18h20: IN2P3-CC_DATADISK: 158 MB/s, IN2P3-CC_DATATAPE: 37 MB/s
no subscriptions/transfers T1-T2 since the very first dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 (vuid = 6403bd5a-5a71-4732-9a0a-b22b56aef106) to GRIF-LAL_DATADISK and TOKYO-LCG2_DATADISK. Transfers to Tokyo has finished. LAL is still Inactive.
21 May 16h40
Since around 16:40 T0-T1 transfers stopped. There are many errors.
SOURCE error during PREPARATION phase: [GENERAL_FAILURE] Error caught in srm::getSrmUser.Error creating statement, Oracle code: 12537ORA-12537: TNS:connection closed] Source Host [srm-atlas.cern.ch]




21 May 13h30
T0-T1 Transfers started at around 13h30.
The overall throughput from T0 is over 1000MB/s.
Lyon is receiving its share at 100-200 MB/s (verying with time).
the average rate is about 40MB/s to IN2P3-CC_DATADISK
and 140MB/s to IN2P3-CC_DATATAPE according to dashb http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site?name=LYON.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
T1-T2 Transfers started at around 15h10. http://lcg2.in2p3.fr/wiki/images/20080521-1530-LYONT2.throughput.14400.png
{kind=link}
- from dq2.log:
- 2008-05-21 15:00: SubscriptionQueued for dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 (vuid = 6403bd5a-5a71-4732-9a0a-b22b56aef106) to GRIF-LAL_DATADISK and TOKYO-LCG2_DATADISK
- 2008-05-21 15:00: FileTransferring: 3 files of the dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 (fsize = 3600000000 each) for both TOKYO-LCG2_DATADISK and GRIF-LAL_DATADISK
- 2008-05-21 15:03: VALIDATED: 3 files of dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 at srm://lcg-se01.icepp.jp
- 2008-05-21 15:03: FileCopied: 3 files of dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 at TOKYO-LCG2_DATADISK
- 2008-05-21 15:03: FileDone: 3 files of dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 at TOKYO-LCG2_DATADISK
- 2008-05-21 15:05: SubscriptionComplete: vuid = 6403bd5a-5a71-4732-9a0a-b22b56aef106 : site = TOKYO-LCG2_DATADISK : dsn = ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 : version = 1
- FTS channels for LAL are 'Inactive' for 'Pb clim LAL'
T0-T1-T2 + T1-T1 transfer tests (week4)
- Plan
ADC Oper 22 May (slide 8 - 10) http://indico.cern.ch/materialDisplay.py?contribId=3&materialId=slides&confId=34556
Datasets are subscribed to T1s from partner Tier-1s ~ every 2h
Datasets are subscribed to T2s from parent Tier-1s ~ every 4h