Difference between revisions of "Atlas:CCRC08May"
(→T0-T1-T2 + T1-T1 transfer tests (week4)) |
(→Fri, 30 May) |
||
| (40 intermediate revisions by the same user not shown) | |||
| Ligne 1: | Ligne 1: | ||
| + | = Monitoring pages/graphs = | ||
| + | === FTS === | ||
| + | http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsmonitor.php?vo=atlas | ||
| + | |||
| + | === T0-T1 (ALL) === | ||
| + | http://atldq2pro.cern.ch:8000/ft/mon/ftmon_tier1s.html | ||
| + | |||
| + | http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site | ||
| + | *Throughput<br> | ||
| + | :http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/OVERVIEW.throughput.14400.png | ||
| + | *Errors<br> | ||
| + | :http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/OVERVIEW.num_file_xs_error.14400.png | ||
| + | |||
| + | === T0-T1 (Lyon) === | ||
| + | http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site?statsInterval=4&name=LYON | ||
| + | *Throughput T0-LYON<br> | ||
| + | :http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/LYON.throughput.14400.png | ||
| + | *Errors T0-LYON<br> | ||
| + | :http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/LYON.num_file_xs_error.14400.png | ||
| + | *Throughput Others-LYON<br> | ||
| + | :http://dashb-atlas-data.cern.ch/dashboard/templates/plots/LYON.T1.throughput.14400.png | ||
| + | *Errors Others-LYON<br> :http://dashb-atlas-data.cern.ch/dashboard/templates/plots/LYON.T1.num_file_xs_error.14400.png | ||
| + | |||
| + | === T1-T1 === | ||
| + | http://atldq2pro.cern.ch:8000/ft/mon/ftmon_T1-T1.html | ||
| + | |||
| + | === T1-T2 (Lyon) === | ||
| + | http://atldq2pro.cern.ch:8000/ft/mon/ftmon_tier2s.html | ||
| + | http://atldq2pro.cern.ch:8000/ft/mon/ftmon_T1-T2_matrix_day.html | ||
| + | |||
| + | http://dashb-atlas-data.cern.ch/dashboard/request.py/site?statsInterval=4&name=LYON | ||
| + | *Throughput<br> | ||
| + | :http://dashb-atlas-data.cern.ch/dashboard/templates/plots/LYON.T2.throughput.14400.png | ||
| + | *Errors | ||
| + | :http://dashb-atlas-data.cern.ch/dashboard/templates/plots/LYON.T2.num_file_xs_error.14400.png | ||
| + | |||
| + | === Network Graphs === | ||
| + | ; IN2P3 Weathermap | ||
| + | * http://netstat.in2p3.fr/weathermap/ | ||
| + | * http://netstat.in2p3.fr/weathermap/graphiques/ | ||
| + | |||
| + | ; cc-in2p3 : [http://netstat.in2p3.fr/weathermap/graphiques/lyo-cern.html lyo-cern] (lhcopn-in2p3.cern.ch)<br> http://netstat.in2p3.fr/weathermap/graphiques/lyo-cern-daily.gif | ||
| + | ; lyon-nord : [http://netstat.in2p3.fr/weathermap/graphiques/lyo-nrd.html lyo-nrd] <br> http://netstat.in2p3.fr/weathermap/graphiques/lyo-nrd-daily.gif | ||
| + | ; orsay : [http://netstat.in2p3.fr/weathermap/graphiques/orsay.html orsay] (in2p3-orsay.cssi.renater.fr<br> http://netstat.in2p3.fr/weathermap/graphiques/orsay-daily.gif | ||
| + | ; lal-cc : [http://netstat.in2p3.fr/weathermap/graphiques/lal-cc.html Liaison LAL - CC]<br> http://netstat.in2p3.fr/weathermap/graphiques/lal-cc-daily.gif | ||
| + | ; lal : [http://netstat.in2p3.fr/weathermap/graphiques/lal.html lal]<br> http://netstat.in2p3.fr/weathermap/graphiques/lal-daily.gif | ||
| + | ; lpnhe: [http://netstat.in2p3.fr/weathermap/graphiques/lpnhe-nrd.html lpnhe-nrd] (in2p3-jussieu.cssi.renater.fr)<br> http://netstat.in2p3.fr/weathermap/graphiques/lpnhe-nrd-daily.gif<br> [http://netstat.in2p3.fr/weathermap/graphiques/lpnhe.html lpnhe] (Paris-LPNHE.in2p3.fr)<br> http://netstat.in2p3.fr/weathermap/graphiques/lpnhe-daily.gif | ||
| + | ; lapp : [http://netstat.in2p3.fr/weathermap/graphiques/ann-nrd.html ann-nrd] <br> http://netstat.in2p3.fr/weathermap/graphiques/ann-nrd-daily.gif | ||
| + | ; lpc: [http://netstat.in2p3.fr/weathermap/graphiques/lpc-cf.html lpc-cf] | ||
| + | http://netstat.in2p3.fr/weathermap/graphiques/lpc-cf-daily.gif | ||
| + | ; lpsc : [http://netstat.in2p3.fr/weathermap/graphiques/lpsc.html lpsc]<br> http://netstat.in2p3.fr/weathermap/graphiques/lpsc-daily.gif | ||
| + | ; cppm : [http://netstat.in2p3.fr/weathermap/graphiques/cppm.html cppm]<br> | ||
| + | http://netstat.in2p3.fr/weathermap/graphiques/cppm-daily.gif | ||
| + | ; international (tokyo etc.) : [http://netstat.in2p3.fr/weathermap/graphiques/parisnrd.html parisnrd]<br> | ||
| + | http://netstat.in2p3.fr/weathermap/graphiques/parisnrd-daily.gif | ||
| + | ; GEANT - NYC : [http://dc-snmp.wcc.grnoc.iu.edu/manlan/show-graph.cgi?title=sw.newy32aoa.manlan.internet2.edu--te10/1&rrdname=sw.newy32aoa.manlan.internet2.edu--te10_1.rrd MANLAN]<br> | ||
| + | http://dc-snmp.wcc.grnoc.iu.edu/manlan/img/sw.newy32aoa.manlan.internet2.edu--te10_1-std5.gif | ||
| + | ; NYC - TOKYO : [http://dc-snmp.wcc.grnoc.iu.edu/manlan/show-graph.cgi?title=sw.newy32aoa.manlan.internet2.edu--te11/1&rrdname=sw.newy32aoa.manlan.internet2.edu--te11_1.rrd MANLAN]<br> | ||
| + | http://dc-snmp.wcc.grnoc.iu.edu/manlan/img/sw.newy32aoa.manlan.internet2.edu--te11_1-std5.gif | ||
| + | ; tokyo : [http://www.icepp.jp/monitor/gridftp/monitor.html gridftp monitor]<br> http://www.icepp.jp/monitor/gridftp/img/all.png | ||
| + | |||
= T0-T1 transfer tests (week1) = | = T0-T1 transfer tests (week1) = | ||
= T1-T1 transfer tests (week2) = | = T1-T1 transfer tests (week2) = | ||
| Ligne 134: | Ligne 195: | ||
* TOKYO-LCG2_DATADISK : (lcg-admin a icepp.s.u-tokyo.ac.jp) | * TOKYO-LCG2_DATADISK : (lcg-admin a icepp.s.u-tokyo.ac.jp) | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
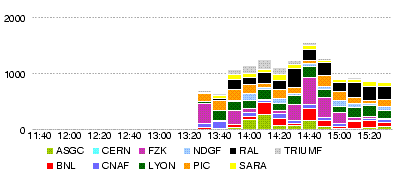
== Summary == | == Summary == | ||
| Ligne 442: | Ligne 458: | ||
still with many errors | still with many errors | ||
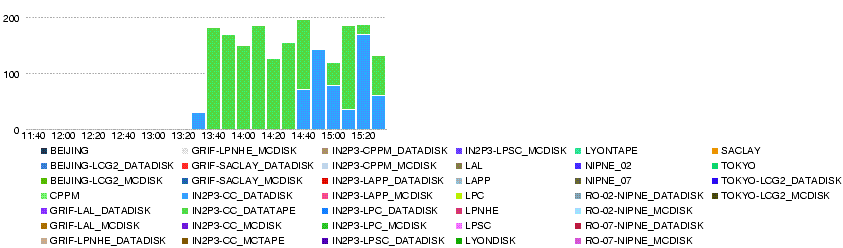
| − | === 22 May === | + | === Thu, 22 May === |
| − | ;Throughput | + | http://dashb-atlas-data.cern.ch/dashboard/request.py/site?name=LYON&fromDate=2008-05-22%2000:00&toDate=2008-05-23%2000:00 |
| − | [[Image:LYON.throughput.20080522.png]] | + | ;Throughput (MB/s) within LYON cloud (T0-LYON + LYON-T2s) during the day 22 May :[[Image:LYON.throughput.20080522.png]] |
| − | ; | + | ;Number of errors within LYON cloud (T0-LYON + LYON-T2s) during the day 22 May :[[Image:LYON.num file xs error.20080522.png]] |
| − | [[Image:LYON.num file xs error.20080522.png]] | ||
* There was a network problem for Romanian national Internet provider RoEdu from 6:30 to 10 GMT, according to Titi and Mihai. | * There was a network problem for Romanian national Internet provider RoEdu from 6:30 to 10 GMT, according to Titi and Mihai. | ||
| Ligne 524: | Ligne 539: | ||
<span style="color:#FF0000;">'''And the graphs can also be wrong'''</span> | <span style="color:#FF0000;">'''And the graphs can also be wrong'''</span> | ||
| − | ;Throughput all T0-T1 | + | ;Throughput (MB/s) all T0-T1 during the day 21 May :[[Image:OVERVIEW.throughput.20080521.png]] |
| − | [[Image:OVERVIEW.throughput.20080521.png]] | + | ;Throughtput (MB/s) T0-LYON during the day 21 May :[[Image:LYON.throughput.20080521-1.png]] |
| − | ;Throughtput T0-LYON | + | ;Throughput (MB/s) LYON-T2 during the day 21 May :[[Image:LYON.T2.throughput.20080521.png]] |
| − | [[Image:LYON.throughput.20080521-1.png]] | ||
| − | ;Throughput LYON-T2 | ||
| − | [[Image:LYON.T2.throughput.20080521.png]] | ||
| Ligne 553: | Ligne 565: | ||
; 21 May 20h20 | ; 21 May 20h20 | ||
| − | dashb shows transfers, which seem to be successful but with many registration errors, in the table (not in the graph). Looking into the details, file states are 'ATTEMPT_DONE' with 'HOLD_FAILED_REGISTRATION' | + | dashb shows transfers, which seem to be successful but with many registration errors, in the table (not in the graph). Looking into the details, file states are 'ATTEMPT_DONE' with 'HOLD_FAILED_REGISTRATION'. Errors in registration do not seem to appear on the error graph which is for transfer errors. |
| + | ::Throughput LYON-T2 (MB/s) | ||
::[[Image:LYON.T2.throughput.14400.20080521-2028.png]] | ::[[Image:LYON.T2.throughput.14400.20080521-2028.png]] | ||
| Ligne 601: | Ligne 614: | ||
Source Host [srm-atlas.cern.ch] | Source Host [srm-atlas.cern.ch] | ||
</pre> | </pre> | ||
| + | ::Overall throughput T0-T1s 21 May 13h - 17h <br> | ||
::[[Image:OVERVIEW.throughput.14400.20080521-1300-1700.png]]<br> | ::[[Image:OVERVIEW.throughput.14400.20080521-1300-1700.png]]<br> | ||
| + | ::Overall number of errors T0-T1s 21 May 13h - 17h <br> | ||
::[[Image:OVERVIEW.num file xs error.14400.20080521-1300-1700.png]] | ::[[Image:OVERVIEW.num file xs error.14400.20080521-1300-1700.png]] | ||
| + | ::Overall throughput T0-Lyon 21 May 13h - 17h <br> | ||
::[[Image:LYON.throughput.14400.20080521-1300-1700.png]] | ::[[Image:LYON.throughput.14400.20080521-1300-1700.png]] | ||
| + | ::Overall number of errors T0-Lyon 21 May 13h - 17h <br> | ||
::[[Image:LYON.num file xs error.14400.20080521-1300-1700.png]] | ::[[Image:LYON.num file xs error.14400.20080521-1300-1700.png]] | ||
<br> | <br> | ||
| Ligne 614: | Ligne 631: | ||
the average rate is about 40MB/s to IN2P3-CC_DATADISK | the average rate is about 40MB/s to IN2P3-CC_DATADISK | ||
and 140MB/s to IN2P3-CC_DATATAPE according to dashb http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site?name=LYON. | and 140MB/s to IN2P3-CC_DATATAPE according to dashb http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site?name=LYON. | ||
| + | :Overall throughput T0-T1s in 4h up to 15h30 21 May<br> | ||
:[[Image:20080521-1530-OVERVIEW.throughput.14400.png]] | :[[Image:20080521-1530-OVERVIEW.throughput.14400.png]] | ||
| + | :Throughput T0-Lyon in 4h up to 15h30 21 May<br> | ||
:[[Image:20080521-1530-LYON.throughput.14400.png]] | :[[Image:20080521-1530-LYON.throughput.14400.png]] | ||
| Ligne 628: | Ligne 647: | ||
* FTS channels for LAL are 'Inactive' for 'Pb clim LAL' | * FTS channels for LAL are 'Inactive' for 'Pb clim LAL' | ||
| − | = Extra tests | + | = Extra tests = |
| + | == GRIF (26 May) == | ||
; 26 May 12h50 | ; 26 May 12h50 | ||
; Througput (MB/s) : [[Image:LYON.T2.throughput.14400.20080526-1250.png]] | ; Througput (MB/s) : [[Image:LYON.T2.throughput.14400.20080526-1250.png]] | ||
| Ligne 638: | Ligne 658: | ||
; Errors : [[Image:LYON.T2.num file xs error.14400.20080526-1214.png]] | ; Errors : [[Image:LYON.T2.num file xs error.14400.20080526-1214.png]] | ||
| − | = | + | == BEIJING (26 May) == |
| + | ; 27 May 14h15 | ||
| + | Erming: | ||
| + | I tuned the IN2P3-BEIJING channel to 20 concurrent files and 5 concurrent streams. I tested many combinations: | ||
| + | Nofiles NoStreams | ||
| + | 5 3 | ||
| + | 10 5 | ||
| + | 15 5 | ||
| + | 20 5 | ||
| + | 20 10 | ||
| + | 25 5 | ||
| + | 30 5 | ||
| + | |||
| + | It appears that 20/5 is the best for the moment which can reach more than 80MB/s throughput. | ||
| + | |||
| + | |||
| + | ; 26 May | ||
| + | Number of concurrent files increased, and tested. | ||
| − | ; | + | ;Throughput (MB/s):[[Image:LYON.T2.throughput.20080526-1710-2110.png]] |
| + | ;Errors:[[Image:LYON.T2.num file xs error.20080526-1710-2110.png]] | ||
| + | = T0-T1-T2 + T1-T1 transfer + MC production (week4) = | ||
| + | == Plan == | ||
ADC Oper 22 May (slide 8 - 10) | ADC Oper 22 May (slide 8 - 10) | ||
http://indico.cern.ch/materialDisplay.py?contribId=3&materialId=slides&confId=34556 | http://indico.cern.ch/materialDisplay.py?contribId=3&materialId=slides&confId=34556 | ||
| + | |||
| + | Friday morning: data generation stops | ||
| + | |||
; T0-T1-T2 : Datasets named ccrc08_run2.018* produced at the nominal rate | ; T0-T1-T2 : Datasets named ccrc08_run2.018* produced at the nominal rate | ||
| − | ; T1-T1 : Datasets named ccrc08_run2.017* (ESD+AOD only, no RAW) produced at the nominal rate. | + | ; T1-T1 : Datasets named ccrc08_run2.017* (ESD+AOD only, no RAW) produced at the nominal rate (up to 29 May in the morning). |
:The ESDs are replicated only between the paired T1s during the first two days. AODs are replicated to everywhere. | :The ESDs are replicated only between the paired T1s during the first two days. AODs are replicated to everywhere. | ||
| + | :Datasets named ccrc08_run2.019* (ESD+AOD only, no RAW) produced at the nominal rate (since 29 May in the morning) | ||
:The ESDs are replicated from every T1 to every other T1s for the last two days. | :The ESDs are replicated from every T1 to every other T1s for the last two days. | ||
| Ligne 661: | Ligne 705: | ||
ESD: in from T0: 15%+15% nominal = 3TB/day | ESD: in from T0: 15%+15% nominal = 3TB/day | ||
| − | in from partner T1: 15% nominal = 1.5TB/day (at first) | + | in from partner T1 (60% of BNL): 15% nominal = 1.5TB/day (at first) |
| − | in from all other T1: | + | in from all other T1: 85% nominal = 8.5TB/day (later) |
out to partner T1: 15% nominal = 1.5TB/day (at first) | out to partner T1: 15% nominal = 1.5TB/day (at first) | ||
out to all other T1: 9*15% nominal = 13.5TB/day (later) | out to all other T1: 9*15% nominal = 13.5TB/day (later) | ||
| Ligne 673: | Ligne 717: | ||
total in: 2.4TB/day on tape, 28MB/s, 9.6TB/4d | total in: 2.4TB/day on tape, 28MB/s, 9.6TB/4d | ||
in: 6.5TB/day on disk, 75MB/s, 26TB/4d (first) | in: 6.5TB/day on disk, 75MB/s, 26TB/4d (first) | ||
| − | in: | + | in: 13.5TB/day on disk, 156MB/s (later) |
out to T1s 2.85TB/day, 33MB/s (first) | out to T1s 2.85TB/day, 33MB/s (first) | ||
out to T1s 15TB/day, 172MB/s (later) | out to T1s 15TB/day, 172MB/s (later) | ||
| Ligne 683: | Ligne 727: | ||
Datasets are subscribed to T2s from parent Tier-1s ~ every 4h | Datasets are subscribed to T2s from parent Tier-1s ~ every 4h | ||
| + | |||
| + | == T0 - T1 == | ||
| + | |||
| + | * Monitor page: http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T0toT1s | ||
== T1 - T2 == | == T1 - T2 == | ||
| + | * Monitor page: http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT2s | ||
| + | |||
| + | * Shares requested for the T2s, and data volume estimation done by I.Ueda | ||
* IN2P3-LAPP_DATADISK : 25% 0.25TB/d, 2.9MB/s, 1.0TB/4d | * IN2P3-LAPP_DATADISK : 25% 0.25TB/d, 2.9MB/s, 1.0TB/4d | ||
* IN2P3-CPPM_DATADISK : 5% 0.05TB/d, 0.6MB/s, 0.2TB/4d | * IN2P3-CPPM_DATADISK : 5% 0.05TB/d, 0.6MB/s, 0.2TB/4d | ||
| Ligne 699: | Ligne 750: | ||
------------------------------------------------------------------ | ------------------------------------------------------------------ | ||
Total : 300% 3.0 TB/d, 34.7MB/s, 12.0TB/4d | Total : 300% 3.0 TB/d, 34.7MB/s, 12.0TB/4d | ||
| + | |||
| + | * Tue, 27 May 2008 17:17:29 +0200, From: Alexei Klimentov | ||
| + | - subscriptions from T1 to parent T2s are done every 3-4h | ||
| + | - local file catalogs are checked every 2h | ||
| + | http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT2s | ||
| + | There were several requests to change '%%' | ||
| + | I attach the last table I am using (there are 48 T2s participating) | ||
| + | line INFN-FRASCATI_DATADISK | 25 | INFN-MILANO_DATADISK | ||
| + | means that INFN-FRASCATI_DATADISK will be subscribed to 25% of AODs | ||
| + | from CNAF and datasets@FRASCATI shouldn't overlap with the | ||
| + | datasets@MILANO | ||
| + | |||
| + | Subscriptions are done using my certificate | ||
| + | |||
| + | ; Alexei's table for T2s | ||
| + | GRIF-LAL_DATADISK 45 GRIF-LPNHE_DATADISK,GRIF-SACLAY_DATADISK | ||
| + | GRIF-LPNHE_DATADISK 25 GRIF-SACLAY_DATADISK,GRIF-LAL_DATADISK | ||
| + | GRIF-SACLAY_DATADISK 30 GRIF-LPNHE_DATADISK,GRIF-LAL_DATADISK | ||
| + | IN2P3-CPPM_DATADISK 5 IN2P3-LAPP_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK | ||
| + | IN2P3-LAPP_DATADISK 25 IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK | ||
| + | IN2P3-LPC_DATADISK 25 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK | ||
| + | IN2P3-LPSC_DATADISK 5 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK | ||
| + | RO-02-NIPNE_DATADISK 10 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING_DATADISK,RO-07-NIPNE_DATADISK | ||
| + | RO-07-NIPNE_DATADISK 10 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING_DATADISK,RO-02-NIPNE_DATADISK | ||
| + | TOKYO-LCG2_DATADISK 100 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK | ||
| + | |||
| + | == T1 - T1 == | ||
| + | * Date: Tue, 27 May 2008 17:17:29 +0200, From: Alexei Klimentov | ||
| + | - subscriptions are done every 2h | ||
| + | - local file catalogs are checked every hour | ||
| + | http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT1s | ||
| + | ESD subscriptions | ||
| + | BNL : all ccrc08_run2.0170*ESD* datasets | ||
| + | Other sites : | ||
| + | line | FZK-LCG2_DATADISK | 40 | BNL-OSG2_DATADISK | | ||
| + | means FZK is subscribed to 40% of ccrc08_run2.0170*ESD* from BNL | ||
| + | (important, 40% calculated from the number of completed datasets | ||
| + | at BNL) | ||
| + | 40% at FZK and 60% at LYON shouldn't overlap | ||
| + | (ditto, for INFN and NIKHEF) | ||
| + | subscription is done with '--source' and w/o '--wait-for-source' | ||
| + | options | ||
| + | subscriptions are done using Kors cert | ||
| + | |||
| + | +------------------------+------------+------------------------+ | ||
| + | | tier1 | percentage | tier1_pair | | ||
| + | +------------------------+------------+------------------------+ | ||
| + | | FZK-LCG2_DATADISK | 40 | BNL-OSG2_DATADISK | | ||
| + | | IN2P3-CC_DATADISK | 60 | BNL-OSG2_DATADISK | | ||
| + | | INFN-T1_DATADISK | 50 | RAL-LCG2_DATADISK | | ||
| + | | NDGF-T1_DATADISK | 100 | PIC_DATADISK | | ||
| + | | NIKHEF-ELPROD_DATADISK | 50 | RAL-LCG2_DATADISK | | ||
| + | | PIC_DATADISK | 100 | NDGF-T1_DATADISK | | ||
| + | | RAL-LCG2_DATADISK | 100 | INFN-T1_DATADISK | | ||
| + | | RAL-LCG2_DATADISK | 100 | NIKHEF-ELPROD_DATADISK | | ||
| + | | TAIWAN-LCG2_DATADISK | 100 | TRIUMF-LCG2_DATADISK | | ||
| + | | TRIUMF-LCG2_DATADISK | 100 | TAIWAN-LCG2_DATADISK | | ||
| + | +------------------------+------------+------------------------+ | ||
| + | |||
| + | == Logbook == | ||
| + | === Fri, 30 May === | ||
| + | ;30 May 14h33: CERN-IN2P3 link intervention | ||
| + | Subject: [CERN-LHCOPN] Emergency maintenance NOW - CERN-IN2P3 link affected | ||
| + | |||
| + | Following the power incident this morning we have detected a problem on | ||
| + | the router module that connect to IN2P3. We need to immediately | ||
| + | intervene on it. | ||
| + | |||
| + | DATE AND TIME: | ||
| + | Friday 30th of June 14:20 to 15:00 CEST | ||
| + | |||
| + | IMPACT: | ||
| + | The link LHCOPN CERN-IN2P3 will flap several time. Traffic to IN2P3 will | ||
| + | be rerouted to the backup path. | ||
| + | |||
| + | |||
| + | ;30 May 11h05: [http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site dashb-t0] has also been back. | ||
| + | :'''T0-T1s Throughput (MB/s)'''<br> [[Image:Atlas-dashb-t0-OVERVIEW.throughput.14400.20080530-1105.png]] | ||
| + | :'''T0-LYON Throughput (MB/s)'''<br> [[Image:Atlas-dashb-t0-LYON.throughput.14400.20080530-1105.png]] | ||
| + | :'''T0-LYON Number of files'''<br> [[Image:Atlas-dashb-t0-LYON.num file xs.14400.20080530-1105.png]] | ||
| + | :'''T0-LYON Number of errors'''<br> [[Image:Atlas-dashb-t0-LYON.num file xs error.14400.20080530-1105.png]] | ||
| + | :'''LYON-T2s Throughput (MB/s)'''<br> [[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080530-1105.png]] | ||
| + | :'''LYON-T2s Number of files''' <br> [[Image:Atlas-dashb-prod-LYON.T2.num file xs.14400.20080530-1105.png]] | ||
| + | :'''LYON-T2s Number of errors''<br> [[Image:Atlas-dashb-prod-LYON.T2.num file xs error.14400.20080530-1105.png]] | ||
| + | |||
| + | |||
| + | ;30 May 10h35: [http://dashb-atlas-data.cern.ch/dashboard/request.py/site dashb-prod] is back | ||
| + | |||
| + | ;30 May 9h00: The plan was to stop the data generation at T0 during the morning, but there was a CERN wide powercut (see http://cern.ch/ssb), so this was the end of the generation. We just wait and see all the subscriptions to be processed and replication to be completed. | ||
| + | :A snapshot will be taken at noon tomorrow - subscriptions and monitoring by Alexei will be stopped - and then all the ccrc08_run2 data will be deleted. | ||
| + | :dashb monitors are still down - [http://dashb-atlas-data.cern.ch/dashboard/request.py/site dashb-prod] shows the graphs only up to 04:50, [http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site dashb-t0] still not accessible. | ||
| + | |||
| + | === Thu, 29 May === | ||
| + | ;Snapshot of the replication monitor page: at 05.30 00:05 (cannot tell the cache time -- the numbers as of what time)<br> [[Image:Atlas-ListT1T2-20080530-0005. | ||
| + | ;T0-Lyon Throughput (MB/s) during the day 29 May :[[Image:Atlas-dashb-t0-LYON.T1.throughput.86400.20080530-0005.png]] | ||
| + | ;T0-Lyon Number of files during the day 29 May :[[Image:Atlas-dashb-t0-LYON.T1.num file xs.86400.20080530-0005.png]] | ||
| + | ;T0-Lyon Errors:[[Image:Atlas-dashb-t0-LYON.T1.num file xs error.86400.20080530-0005.png]] | ||
| + | ;Lyon-T2 Throughput (MB/s) during the day 29 May :[[Image:Atlas-dashb-prod-LYON.T2.throughput.86400.20080530-0005.png]] | ||
| + | ;Data volume transferred (GB) during the day 29 May :[[Image:Atlas-dashb-prod-LYON.T2.total bytes xs.86400.20080530-0005.png]] | ||
| + | ;Number of files transferred during the day 29 May :[[Image:Atlas-dashb-prod-LYON.T2.num file xs.86400.20080530-0005.png]] | ||
| + | ;Number of errors in transfers during the day 29 May :[[Image:Atlas-dashb-prod-LYON.T2.num file xs error.86400.20080530-0005.png]] | ||
| + | |||
| + | |||
| + | ;29 May 13h10: [http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT2s The pandamon page for the T1-T2 replication] (cached on Thu, 29 May 2008 09:46:09) showed the following numbers: | ||
| + | BNL | ||
| + | AGLT2_DATADISK 275 | ||
| + | MWT2_DATADISK 275 | ||
| + | NET2_DATADISK 275 | ||
| + | SLACXRD_DATADISK 275 | ||
| + | SWT2_CPB_DATADISK 275 | ||
| + | |||
| + | CNAF | ||
| + | INFN-NAPOLI-ATLAS_DATADISK 275 | ||
| + | INFN-ROMA1_DATADISK 275 | ||
| + | |||
| + | LYON | ||
| + | BEIJING-LCG2_DATADISK 66 | ||
| + | GRIF-LAL_DATADISK 113 | ||
| + | GRIF-LPNHE_DATADISK 68 | ||
| + | GRIF-SACLAY_DATADISK 79 | ||
| + | IN2P3-CPPM_DATADISK 14 | ||
| + | IN2P3-LAPP_DATADISK 68 | ||
| + | IN2P3-LPC_DATADISK 71 | ||
| + | IN2P3-LPSC_DATADISK 14 | ||
| + | RO-02-NIPNE_DATADISK 29 | ||
| + | RO-07-NIPNE_DATADISK 28 | ||
| + | TOKYO-LCG2_DATADISK 254 | ||
| + | :at 11h50, dq2-list-dataset-site tells IN2P3-CC_DATADISK has 258 'ccrc08_run2.018.*AOD' datasets, while INFN-T1_DATADISK has 275 and BNL also. | ||
| + | IN2P3-CC_DATADISK 258 | ||
| + | INFN-T1_DATADISK 275 | ||
| + | TOKYO-LCG2_DATADISK 253 | ||
| + | INFN-NAPOLI-ATLAS_DATADISK 275 | ||
| + | INFN-ROMA1_DATADISK 275 | ||
| + | :Tokyo (254 in the table = assigned, and 253 by dq2 = exist) seems ok, for not all the 258 datasets at Lyon are complete. | ||
| + | :GRIF (113+68+79=260 in the table, 259 by dq2)...? | ||
| + | :Others (290 in the table, 281 by dq2)... too many | ||
| + | IN2P3-LAPP_DATADISK 68 | ||
| + | IN2P3-CPPM_DATADISK 14 | ||
| + | IN2P3-LPSC_DATADISK 14 | ||
| + | IN2P3-LPC_DATADISK 71 | ||
| + | BEIJING-LCG2_DATADISK 59 | ||
| + | RO-07-NIPNE_DATADISK 28 | ||
| + | RO-02-NIPNE_DATADISK 27 | ||
| + | total 281 | ||
| + | :checking with dq2-list-dataset-site, all the datasets in RO-07-NIPNE_DATADISK are also found in BEIJING-LCG2_DATADISK. | ||
| + | |||
| + | |||
| + | |||
| + | ;29 May 9h30: http://cern.ch/ssb ATLAS Castor SRM service intervention between 9:00 and 10:00 am The ATLAS Castor SRM service will be down for one hour to move the backend database to more powerful hardware. There will be no WAN transfers for ATLAS during this period. The rest of Castor ATLAS will not be affected. | ||
| + | |||
| + | |||
| + | ;29 May 9h30 : load generator for T1-T1 datasets has switched from run 017 to run 019. | ||
| + | |||
| + | |||
| + | ;Throughput (MB/s) during 4h up to 29 May 23h05 :[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080529-2305.png]] | ||
| + | ;Throughput (MB/s) during 4h up to 29 May 19h05 :[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080529-1905.png]] | ||
| + | ;Throughput (MB/s) during 4h up to 29 May 15h00 :[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080529-1500.png]] | ||
| + | ;Throughput (MB/s) during 4h up to 29 May 11h00 :[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080529-1100.png]] | ||
| + | ;Throughput (MB/s) during 4h up to 29 May 07h00 :[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080529-0700.png]] | ||
| + | ;Throughput (MB/s) during 4h up to 29 May 03h00 :[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080529-0300.png]] | ||
| + | |||
| + | === Wed, 28 May === | ||
| + | ;Throughput (MB/s) during the day 28 May :[[Image:Atlas-dashb-prod-LYON.T2.throughput.86400.20080529-0100.png]] | ||
| + | ;Data volume transferred (GB) during the day 28 May :[[Image:Atlas-dashb-prod-LYON.T2.total bytes xs.86400.20080529-0100.png]] | ||
| + | ;Number of files transferred during the day 28 May :[[Image:Atlas-dashb-prod-LYON.T2.num file xs.86400.20080529-0100.png]] | ||
| + | ;Number of errors in transfers during the day 28 May :[[Image:Atlas-dashb-prod-LYON.T2.num file xs error.86400.20080529-0100.png]] | ||
| + | |||
| + | |||
| + | ;28 May 13h00 : Being bothered by MC transfer errors with 'file not found' at the source sites (BNLPANDA, NDGFT1DISK), sent Savannah bug items [https://savannah.cern.ch/bugs/index.php?37054 37054], [https://savannah.cern.ch/bugs/index.php?37055 37055] | ||
| + | |||
| + | |||
| + | ;28 May 11h15 : Erros in the last 24h; | ||
| + | Transfers | ||
| + | Site Eff. Succ. Errors | ||
| + | BEIJING-LCG2_DATADISK 75% 134 45 | ||
| + | GRIF-LAL_DATADISK 94% 150 10 | ||
| + | GRIF-LPNHE_DATADISK 99% 99 1 | ||
| + | GRIF-SACLAY_DATADISK 100% 100 0 | ||
| + | IN2P3-CPPM_DATADISK 100% 18 0 | ||
| + | IN2P3-LAPP_DATADISK 99% 95 1 | ||
| + | IN2P3-LPC_DATADISK 100% 101 0 | ||
| + | IN2P3-LPSC_DATADISK 100% 22 0 | ||
| + | RO-02-NIPNE_DATADISK 34% 28 55 | ||
| + | RO-07-NIPNE_DATADISK 100% 38 0 | ||
| + | TOKYO-LCG2_DATADISK 98% 319 7 | ||
| + | |||
| + | {|border=1 | ||
| + | | | ||
| + | |[TRANSFER error during TRANSFER phase: [GRIDFTP] the server sent an error response: 426 426 Transfer aborted (Unexpected Exception : java.io.IOException: Broken pipe)] | ||
| + | |[TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out] | ||
| + | |[TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_gass_copy_register_url_to_url: Connection timed out] | ||
| + | |[SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out] | ||
| + | |[TRANSFER error during TRANSFER phase: [GRIDFTP] an end-of-file was reached (possibly the destination disk is full)] | ||
| + | |[TRANSFER error during TRANSFER phase: [PERMISSION] the server sent an error response: 550 550 rfio write failure: Permission denied.] | ||
| + | |-- | ||
| + | |BEIJING-LCG2_DATADISK | ||
| + | |15 | ||
| + | |14 | ||
| + | |14 | ||
| + | |1 | ||
| + | |1 | ||
| + | |-- | ||
| + | |GRIF-LAL_DATADISK | ||
| + | | | ||
| + | |2 | ||
| + | |7 | ||
| + | |4 | ||
| + | | | ||
| + | |-- | ||
| + | |GRIF-LPNHE_DATADISK | ||
| + | | | ||
| + | | | ||
| + | |1 | ||
| + | |-- | ||
| + | |IN2P3-LAPP_DATADISK | ||
| + | | | ||
| + | | | ||
| + | | | ||
| + | |1 | ||
| + | |-- | ||
| + | |RO-02-NIPNE_DATADISK | ||
| + | |2 | ||
| + | |48 | ||
| + | | | ||
| + | |1 | ||
| + | | | ||
| + | |4 | ||
| + | |-- | ||
| + | |TOKYO-LCG2_DATADISK | ||
| + | | | ||
| + | | | ||
| + | |4 | ||
| + | |3 | ||
| + | |} | ||
| + | |||
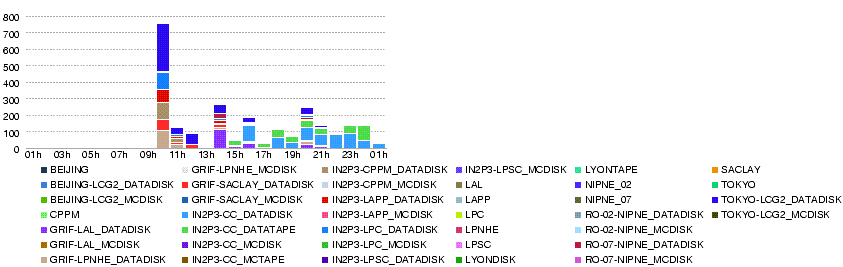
| + | ;28 May 09h00 : Transfers to T2s are going well. | ||
| + | [[Image:Atlas-ListT1T2-20080528-0801.png]] | ||
| + | |||
| + | === Tue, 27 May === | ||
| + | ;Throughput (MB/s) during the day 27 May :[[Image:Atlas-dashb-prod-LYON.T2.throughput.86400.20080528-0100.png]] | ||
| + | ;Volume transferred (GB) during the day 27 May :[[Image:Atlas-dashb-prod-LYON.T2.total bytes xs.86400.20080528-0100.png]] | ||
| + | ;Number of files transferred during the day 27 May :[[Image:Atlas-dashb-prod-LYON.T2.num file xs.86400.20080528-0100.png]] | ||
| + | ;Number of errors in transfers during the day 27 May :[[Image:Atlas-dashb-prod-LYON.T2.num file xs error.86400.20080528-0100.png]] | ||
| + | |||
| + | |||
| + | ;27 May 16h40 : some more info about errors. | ||
| + | * BEIJING has had 11 <pre>[TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_gass_copy_register_url_to_url: Connection timed out]</pre> | ||
| + | * RO-02-NIPNE had 7 <pre>[TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out]</pre> | ||
| + | * and 1 <pre>[SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out]</pre> | ||
| + | * TOKYO-LCG2: 1 <pre>[SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out]</pre> | ||
| + | <!--;Throughput (MB/s):[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080527-1700.png]]--> | ||
| + | ;Number of Files Transferred:[[Image:Atlas-dashb-prod-LYON.T2.num file xs.14400.20080527-1700.png]] | ||
| + | ;Errors:[[Image:Atlas-dashb-prod-LYON.T2.num file xs error.14400.20080527-1700.png]] | ||
| + | |||
| + | |||
| + | ;27 May 14h00 : We reached nearly 700MB/s in total <br>[[Image:Atlas-dashb-prod-LYON.T2.throughput.14400.20080527-14.png]] | ||
| + | :with only small number of errors <br>[[Image:Atlas-dashb-prod-LYON.T2.num file xs error.14400.20080527-14.png]] | ||
| + | |||
| + | |||
| + | ;27 May 11h40 : The T1-T2 transfers have started | ||
| + | |||
| + | ;27 May 09h50 : The T0 data generation has started already yesterday. | ||
| + | The T0 export is being started. (That is, there is a large backlog for T0-T1.) | ||
| + | |||
| + | === Mon, 26 May === | ||
| + | |||
| + | ;26 May 20h00 : Still don't see any ccrc08_run2 datasets being transferred. (the activities for T0-T1 are data08_cosm7). | ||
| + | |||
| + | |||
| + | ;26 May 18h50 : around 18h50 T0-LYON transfers went back to T0 vobox, monitored by T0 dashb. | ||
| + | |||
| + | |||
| + | ;26 May 15h40 : cosmic data transfers ongoing (data08_cosm7, T0-T1) need to wait still more before ccrc data to come out. | ||
Latest revision as of 17:19, 30 mai 2008
Sommaire
Monitoring pages/graphs
FTS
http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsmonitor.php?vo=atlas
T0-T1 (ALL)
http://atldq2pro.cern.ch:8000/ft/mon/ftmon_tier1s.html
http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site
- Throughput
- Errors
- http://dashb-atlas-data-tier0.cern.ch/dashboard/templates/plots/OVERVIEW.num_file_xs_error.14400.png
T0-T1 (Lyon)
http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site?statsInterval=4&name=LYON
- Throughput T0-LYON
- Errors T0-LYON
- Throughput Others-LYON
- Errors Others-LYON
:http://dashb-atlas-data.cern.ch/dashboard/templates/plots/LYON.T1.num_file_xs_error.14400.png
T1-T1
http://atldq2pro.cern.ch:8000/ft/mon/ftmon_T1-T1.html
T1-T2 (Lyon)
http://atldq2pro.cern.ch:8000/ft/mon/ftmon_tier2s.html http://atldq2pro.cern.ch:8000/ft/mon/ftmon_T1-T2_matrix_day.html
http://dashb-atlas-data.cern.ch/dashboard/request.py/site?statsInterval=4&name=LYON
- Throughput
- Errors
Network Graphs
- IN2P3 Weathermap
- cc-in2p3
- lyo-cern (lhcopn-in2p3.cern.ch)
http://netstat.in2p3.fr/weathermap/graphiques/lyo-cern-daily.gif - lyon-nord
- lyo-nrd
http://netstat.in2p3.fr/weathermap/graphiques/lyo-nrd-daily.gif - orsay
- orsay (in2p3-orsay.cssi.renater.fr
http://netstat.in2p3.fr/weathermap/graphiques/orsay-daily.gif - lal-cc
- Liaison LAL - CC
http://netstat.in2p3.fr/weathermap/graphiques/lal-cc-daily.gif - lal
- lal
http://netstat.in2p3.fr/weathermap/graphiques/lal-daily.gif - lpnhe
- lpnhe-nrd (in2p3-jussieu.cssi.renater.fr)
http://netstat.in2p3.fr/weathermap/graphiques/lpnhe-nrd-daily.gif
lpnhe (Paris-LPNHE.in2p3.fr)
http://netstat.in2p3.fr/weathermap/graphiques/lpnhe-daily.gif - lapp
- ann-nrd
http://netstat.in2p3.fr/weathermap/graphiques/ann-nrd-daily.gif - lpc
- lpc-cf
http://netstat.in2p3.fr/weathermap/graphiques/lpc-cf-daily.gif
http://netstat.in2p3.fr/weathermap/graphiques/cppm-daily.gif
- international (tokyo etc.)
- parisnrd
http://netstat.in2p3.fr/weathermap/graphiques/parisnrd-daily.gif
- GEANT - NYC
- MANLAN
http://dc-snmp.wcc.grnoc.iu.edu/manlan/img/sw.newy32aoa.manlan.internet2.edu--te10_1-std5.gif
- NYC - TOKYO
- MANLAN
http://dc-snmp.wcc.grnoc.iu.edu/manlan/img/sw.newy32aoa.manlan.internet2.edu--te11_1-std5.gif
T0-T1 transfer tests (week1)
T1-T1 transfer tests (week2)
Some summaries presented at ADC Operations Meeting http://indico.cern.ch/conferenceDisplay.py?confId=33976
T0-T1-T2 transfer tests (week3)
General remarks
https://twiki.cern.ch/twiki/bin/view/Atlas/DDMOperationsGroup#CCRC08_2_May_2008
The T0 load generator will run at "peak" rate for 3 days ("peak" rate means data from 24h/day of detector data taking at 200Hz are distributed in 24h, while "nominal" rate means data from 14 hours/day of detector data taking at 200Hz are distributed in 24h).
At peak rate 17,280,000 events/day are produced, corresponding to 27.6 TB/day of RAW, 17.3 TB/day of ESD and 3.5 TB/day of AOD (considering the sizes of 1.6 MB/event for RAW, 1.0 MB/event for ESD and 0.2 MB/event for AOD)
- It turned out that AOD size was 0.1 MB/event; 1.7TB/day.
- monitoring page
data replication from CERN to Tier-1s http://panda.atlascomp.org/?mode=listFunctionalTests
data replication within clouds http://panda.atlascomp.org/?mode=listFunctionalTests&testType=T1toT2s
- Summaries / Reports
ADC Oper 22 May http://indico.cern.ch/materialDisplay.py?contribId=3&materialId=slides&confId=34556
T0-T1(LYON)
Shipping continuously data to T1s according to computing model, sites should demonstrate to sustain for 3 days the following export rates
| SITE | TAPE | DISK | TOTAL |
| IN2P3 | 48.00 MB/s | 100.00 MB/s | 148.00 MB/s |
Metric for success: Sites should be capable of sustaining 90% of the mentioned rates (for both disk and tape) for at least 2 days of test. For sites who would like to test higher throughput, we can oversubscribe (both to disk and tape).
As a reminder, here the table of the necessary space needed at each T1
| SITE | TAPE | DISK |
| IN2P3 | 12.4416 TB | 25.92 TB |
replication status is checked ~ every 2h http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests
T1-T2
T2s will receive AODs, which should be generated
at a rate of 3.5TB/day 1.7TB/day.
The amount that each site receives depends on the share
as written in
https://twiki.cern.ch/twiki/bin/view/Atlas/DDMOperationsGroup#CCRC08_2_May_2008
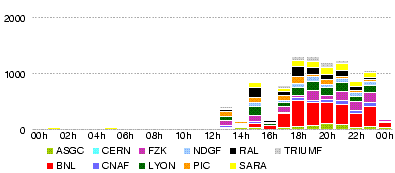
IN2P3-LAPP_DATADISK: 12% 2.4MB/s 0.20TB/day 0.60TB/3d IN2P3-CPPM_DATADISK: 5% 1.0MB/s, 0.09TB/day, 0.27TB/3d IN2P3-LPSC_DATADISK: 5% 1.0MB/s, 0.09TB/day, 0.27TB/3d IN2P3-LPC_DATADISK: 13% 2.6MB/s, 0.22TB/day, 0.66TB/3d GRIF-LAL_DATADISK: 30% 6.0MB/s, 0.51TB/day, 1.53TB/3d GRIF-LPNHE_DATADISK: 15% 3.0MB/s, 0.26TB/day, 0.78TB/3d GRIF-SACLAY_DATADISK: 20% 4.0MB/s, 0.34TB/day, 1.02TB/3d BEIJING-LCG2_DATADISK: 20% 4.0MB/s, 0.34TB/day, 1.02TB/3d RO-07-NIPNE_DATADISK: 10% 2.0MB/s, 0.17TB/day, 0.51TB/3d RO-02-NIPNE_DATADISK: 10% 2.0MB/s, 0.17TB/day, 0.51TB/3d TOKYO-LCG2_DATADISK: 50% 10.MB/s, 0.85TB/day, 2.55TB/3d --------------------------------------------------------------- Total: 190% 37.5MB/s, 3.24TB/day, 9.72TB/3d
The shares are decided rather arbitrary according to the free space in ATLASDATADISK. These numers can be raised at a later stage of the test, but at first we would like to be sure everythinig goes well with this rate.
The shares were increased around 2008-05-24 00:00 (CET)
IN2P3-LAPP_DATADISK : 25% 5.0MB/s, 0.43TB/day, 1.3TB/3d IN2P3-CPPM_DATADISK : 5% 1.0MB/s, 0.09TB/day, 0.3TB/3d IN2P3-LPSC_DATADISK : 5% 1.0MB/s, 0.09TB/day, 0.3TB/3d IN2P3-LPC_DATADISK : 25% 5.0MB/s, 0.43TB/day, 1.3TB/3d BEIJING-LCG2_DATADISK : 20% 4.0MB/s, 0.35TB/day, 1.0TB/3d RO-07-NIPNE_DATADISK : 10% 2.0MB/s, 0.17TB/day, 0.5TB/3d RO-02-NIPNE_DATADISK : 10% 2.0MB/s, 0.17TB/day, 0.5TB/3d GRIF-LAL_DATADISK : 45% 9.0MB/s, 0.77TB/day, 2.3TB/3d GRIF-LPNHE_DATADISK : 25% 5.0MB/s, 0.43TB/day, 1.3TB/3d GRIF-SACLAY_DATADISK : 30% 6.0MB/s, 0.52TB/day, 1.6TB/3d TOKYO-LCG2_DATADISK : 100% 20.0MB/s, 1.73TB/day, 5.2TB/3d ------------------------------------------------------------------ Total : 300% 60.0MB/s, 5.18TB/day, 15.6TB/3d
Datasets are subscribed from parent Tier-1s ~ every 4h
replication status is checked ~ every 2h http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT2s
Lyon FTS monitor: http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsmonitor.php?vo=atlas
Contacts:
- IN2P3-CPPM_DATADISK :
- IN2P3-LPSC_DATADISK :
- IN2P3-LPC_DATADISK :
- GRIF-LAL_DATADISK : (grid.admin a lal.in2p3.fr)
- GRIF-LPNHE_DATADISK :
- GRIF-SACLAY_DATADISK :
- BEIJING-LCG2_DATADISK : (yanxf a ihep.ac.cn, Erming.Pei a cern.ch)
- RO-07-NIPNE_DATADISK : (ciubancan a nipne.ro)
- RO-02-NIPNE_DATADISK : (tpreda a nipne.ro)
- TOKYO-LCG2_DATADISK : (lcg-admin a icepp.s.u-tokyo.ac.jp)
Summary
Short visio conf to summarize what were done this week, and what to prepare for the next week http://indico.in2p3.fr/conferenceDisplay.py?confId=914
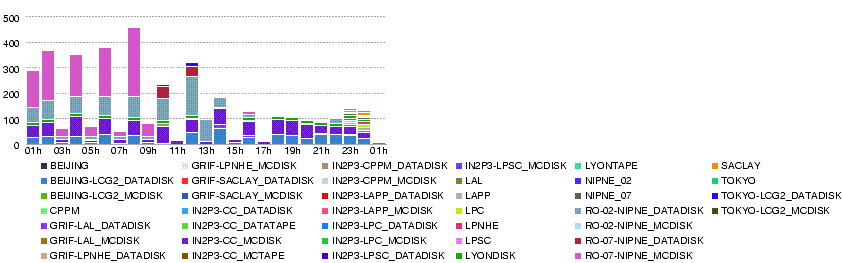
- Statistics from dq2 commands
| site | datasets | files | TB |
| BEIJING-LCG2_DATADISK | 102 | 159 | 0.5724 |
| GRIF-LAL_DATADISK | 231 | 310 | 1.116 |
| GRIF-LPNHE_DATADISK | 136 | 213 | 0.7668 |
| GRIF-SACLAY_DATADISK | 144 | 248 | 0.8928 |
| IN2P3-CPPM_DATADISK | 23 | 39 | 0.1404 |
| IN2P3-LAPP_DATADISK | 129 | 217 | 0.7812 |
| IN2P3-LPC_DATADISK | 136 | 213 | 0.7668 |
| IN2P3-LPSC_DATADISK | 23 | 25 | 0.09 |
| RO-02-NIPNE_DATADISK | 39 | 69 | 0.2484 |
| RO-07-NIPNE_DATADISK | 52 | 99 | 0.3564 |
| TOKYO-LCG2_DATADISK | 626 | 974 | 3.5064 |
dq2 srm free TB Site Share Estimated to be delivered Nds Nf TB End Del Diff. ------------------+----------------------------+-------------+----------- IN2P3-LAPP: 25% 5.0MB/s 0.43TB/day 1.3TB/3d 129 217 0.78 2.319 4.0 1.67TB IN2P3-CPPM: 5% 1.0MB/s 0.09TB/day 0.3TB/3d 23 39 0.14 0.108 0.977 0.87TB IN2P3-LPSC: 5% 1.0MB/s 0.09TB/day 0.3TB/3d 23 25 0.09 0.384 0.384 0.1TB IN2P3-LPC: 25% 5.0MB/s 0.43TB/day 1.3TB/3d 136 213 0.77 1.26 3.0 1.7TB BEIJING-LCG2: 20% 4.0MB/s 0.35TB/day 1.0TB/3d 102 159 0.57 5.557 6.359 0.8TB RO-07-NIPNE: 10% 2.0MB/s 0.17TB/day 0.5TB/3d 52 99 0.36 1.464 2.0 0.5TB RO-02-NIPNE: 10% 2.0MB/s 0.17TB/day 0.5TB/3d 39 69 0.25 2.625 2.831 >0.2TB GRIF-LAL: 45% 9.0MB/s 0.77TB/day 2.3TB/3d 231 310 1.12 3.5 5.844 2.3TB GRIF-LPNHE: 25% 5.0MB/s 0.43TB/day 1.3TB/3d 136 213 0.77 2.24 3.89 1.65TB GRIF-SACLAY: 30% 6.0MB/s 0.52TB/day 1.6TB/3d 144 248 0.89 3.623 5.905 2.3TB TOKYO-LCG2: 100% 20.0MB/s 1.73TB/day 5.2TB/3d 626 974 3.5 3.727 8.738 5TB ------------------+----------------------------+-------------+----------- Total : 300% 60.0MB/s 5.18TB/day 15.6TB/3d
Something wrong with the estimate by dq2? Or, multiple replication of data counts this much?
- cc-in2p3
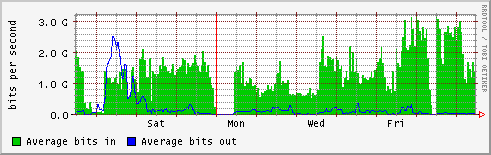
- lyon-nord
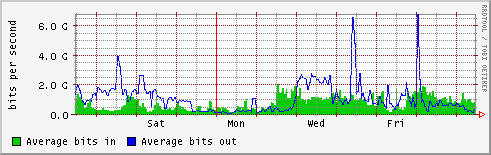
- orsay
- in2p3-orsay.cssi.renater.fr


http://netstat.in2p3.fr/weathermap/graphiques/orsay-weekly.gif
- lal
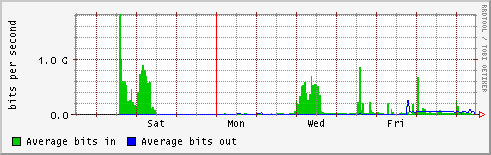
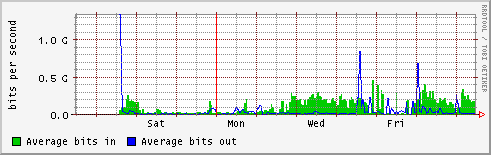
- lpnhe
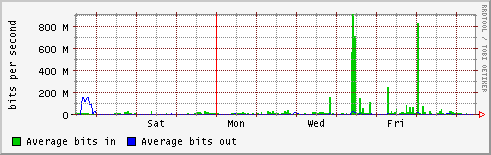
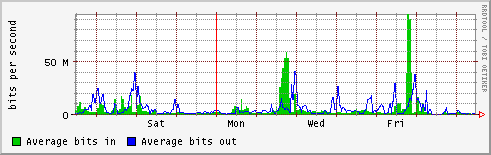
- lapp
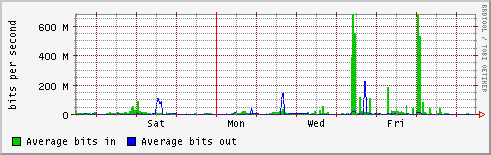
- lpc
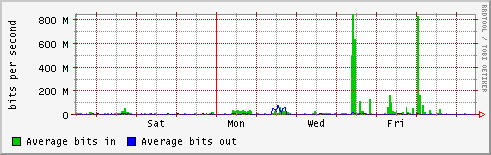
- lpsc
- lpsc
http://netstat.in2p3.fr/weathermap/graphiques/lpsc-weekly.gif - cppm

- international (tokyo etc.)
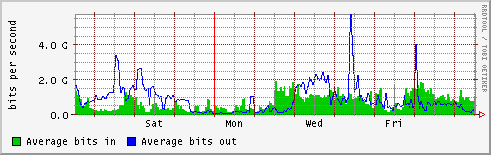
- GEANT - NYC
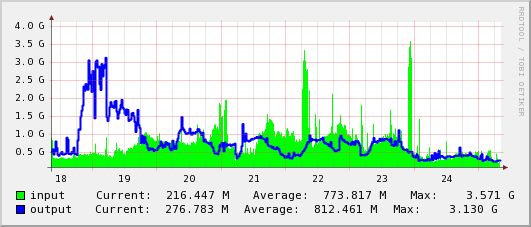
- NYC - TOKYO
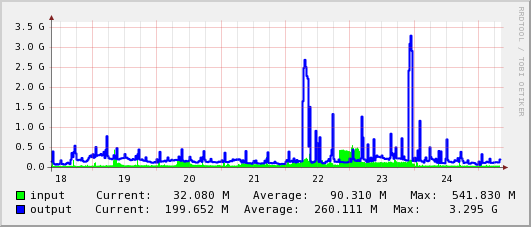
- tokyo

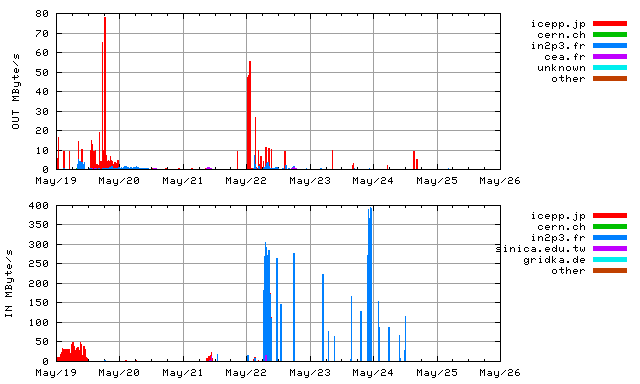












Logbook
Attention! Graphs made by dashb might be wrong.
26 May
- 26 May 10h50
free space
BEIJING-LCG2_DATADISK 6.366 6.366 6.359 GRIF-LAL_DATADISK 6.0 6.0 5.81 GRIF-LPNHE_DATADISK 3.906 3.906 3.89 GRIF-SACLAY_DATADISK 6.0 6.0 5.905 IN2P3-CPPM_DATADISK 1.0 1.0 0.977 IN2P3-LAPP_DATADISK 4.0 4.0 4.0 IN2P3-LPC_DATADISK 3.0 3.0 3.0 IN2P3-LPSC_DATADISK 0.488 0.488 0.384 RO-02-NIPNE_DATADISK 3.0 3.0 2.831 RO-07-NIPNE_DATADISK 0 0 0 TOKYO-LCG2_DATADISK 15.0 15.0 13.738
25 May
Attention! Graphs made by dashb might be wrong.
- Throughput (MB/s)
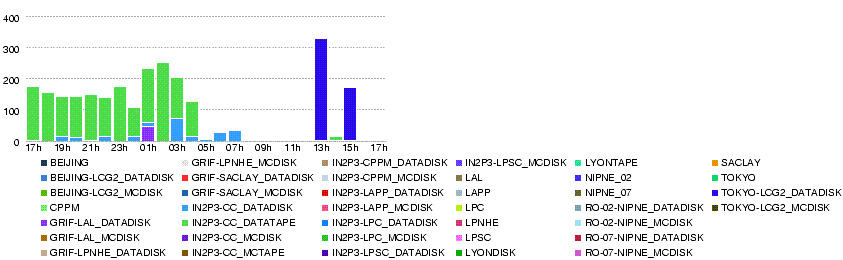
- Volume (GB)
- Number of files

- Number of transfer errors





- 25 May 22h50
free space
BEIJING-LCG2_DATADISK 6.366 6.366 6.359 GRIF-LAL_DATADISK 6.0 6.0 5.844 GRIF-LPNHE_DATADISK 3.906 3.906 3.89 GRIF-SACLAY_DATADISK 6.0 6.0 5.649 IN2P3-CPPM_DATADISK 1.0 1.0 0.977 IN2P3-LAPP_DATADISK 4.0 4.0 4.0 IN2P3-LPC_DATADISK 3.0 3.0 3.0 IN2P3-LPSC_DATADISK 0.488 0.488 0.384 RO-02-NIPNE_DATADISK 3.0 3.0 2.635 RO-07-NIPNE_DATADISK 2.0 2.0 2.0 TOKYO-LCG2_DATADISK 10.0 10.0 5.064
Thus data volumes transferred this week are:
BEIJING-LCG2_DATADISK 6.359 - 5.557 = 0.8TB GRIF-LAL_DATADISK 5.844 - 3.5 = 2.3 TB GRIF-LPNHE_DATADISK 3.89 - 2.24 = 1.65TB GRIF-SACLAY_DATADISK 5.649 - 3.623 = 2TB IN2P3-CPPM_DATADISK 0.977 - 0.108 = 0.87TB IN2P3-LAPP_DATADISK 4.0 - 2.319 = 1.67TB IN2P3-LPC_DATADISK 3.0 - 1.26 = 1.74TB IN2P3-LPSC_DATADISK 0.384 - 0.384 = ? RO-02-NIPNE_DATADISK : cannot estimate due to deletion errors RO-07-NIPNE_DATADISK 2.0 - 1.464 = 0.5TB TOKYO-LCG2_DATADISK : cannot estimate due to re-subscription
- 25 May 14h00
Datasets re-subscribed to tokyo after deletion.




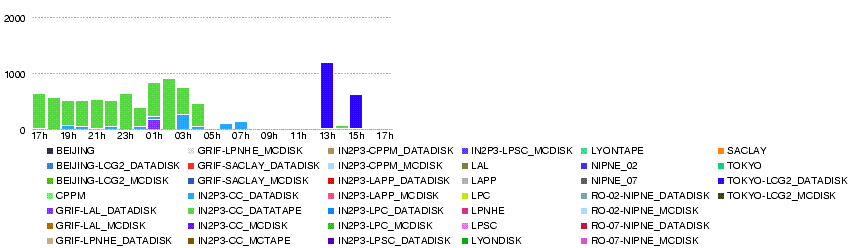
24 May
Attention! Graphs made by dashb might be wrong.
- Throughput (MB/s)
- Volume (GB)
- Number of files
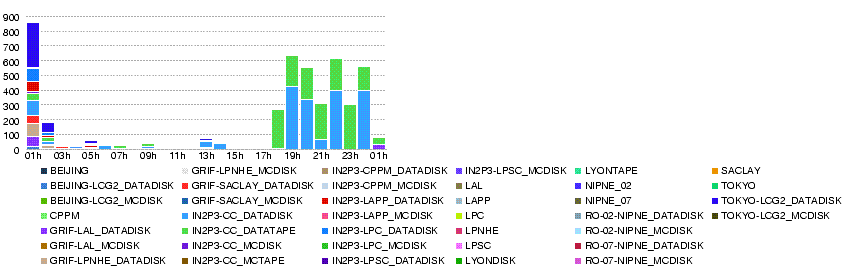
- Number of transfer errors





These graphs show from 01h to 01h, but in fact, the contents are from 00h to 00h.
Since the new shares were applied (around midnight), 3.5TB of data were transferred in 2 hours. That is, the shares were applied also to all the ccrc08_run2 data in the past.
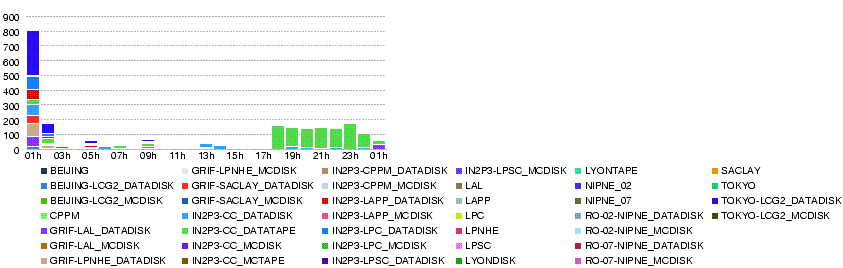
Attention! Graphs made by dashb might be wrong.
- Number of files as snapshot of "last 24h" at 19h46
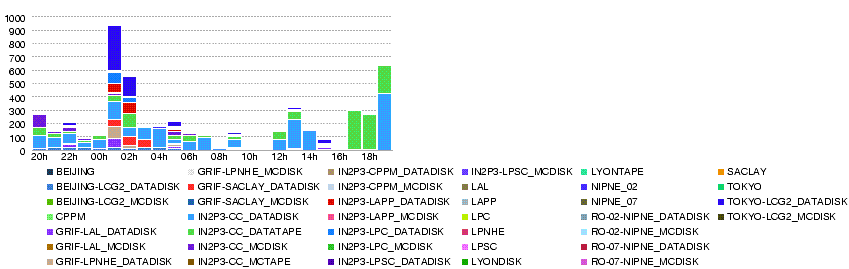
- Number of transfer errors

- Number of transfer errors




- 24 May 23h50
free space
BEIJING-LCG2_DATADISK 6.366 6.366 5.557 GRIF-LAL_DATADISK 6.0 6.0 3.5 GRIF-LPNHE_DATADISK 3.906 3.906 2.24 GRIF-SACLAY_DATADISK 6.0 6.0 3.623 IN2P3-CPPM_DATADISK 1.0 1.0 0.108 IN2P3-LAPP_DATADISK 4.0 4.0 2.319 IN2P3-LPC_DATADISK 3.0 3.0 1.26 IN2P3-LPSC_DATADISK 0.488 0.488 0.384 RO-02-NIPNE_DATADISK 3.0 3.0 2.625 RO-07-NIPNE_DATADISK 2.0 2.0 1.464 TOKYO-LCG2_DATADISK 10.0 10.0 3.727
datasets
BEIJING-LCG2_DATADISK 102 GRIF-LAL_DATADISK 231 GRIF-LPNHE_DATADISK 136 GRIF-SACLAY_DATADISK 144 IN2P3-CPPM_DATADISK 23 IN2P3-LAPP_DATADISK 129 IN2P3-LPC_DATADISK 136 IN2P3-LPSC_DATADISK 23 RO-02-NIPNE_DATADISK 39 RO-07-NIPNE_DATADISK 52 TOKYO-LCG2_DATADISK 626
- 24 May 14h00
Since 11h10-20, T0 exports are resumed, still with some errors but much less. the overall rate (T0-T1 but to Lyon) went over 1000MB/s, and sustained >900MB/s untill 12h10. then started decreasing. likely T0 load generation has stopped.
- 24 May 07h30
apparently, srm.cern.ch is down since 2008-05-24 06:56:26 (dashb). GGUS-Ticket 36761 has been created.
[FTS] FTS State [Failed] FTS Retries [1] Reason [SOURCE error during PREPARATION phase: [GENERAL_FAILURE] Error caught in srm::getSrmUser.Error creating statement, Oracle code: 18ORA-00018: maximum number of sessions exceeded] Source Host [srm-atlas.cern.ch]
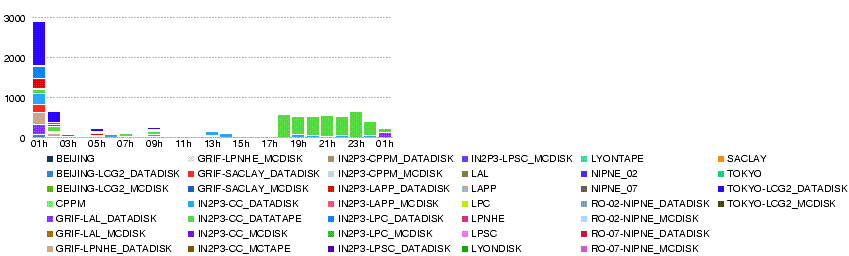
In fact, it may not be down, but just too busy with too many accesses. Seems to have recovered 07h50. But down again? 08h30.
- Throughput
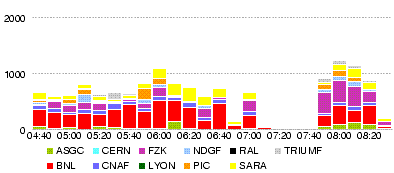
- Errors


- 24 May 00h14
Stephane noticed the new shares had been applied. It seems the subscriptions are made taking all the ccrc08_run2 data into account, not only from now on. That is, we will get much more data and rate than is expected from the shares.
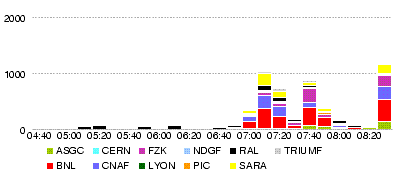
- Throughput

- Errors
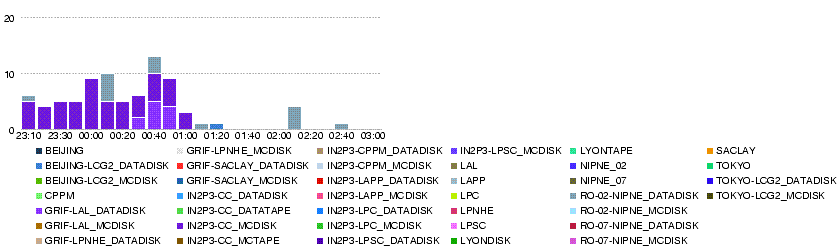


Most of the errors are for IN2P3-CC_DATADISK (305: can't see the cause on dashb), IN2P3-CC_DATATAPE (168: can't see the cause on dashb), IN2P3-CC_MCDISK (80: source error at bnl), RO-02-NIPNE_DATADISK (33: TRANSFER_TIMEOUT, PERMISSION)
- LPC

23 May
- Throughput

- Errors

- 23 May 20h00
many failures to IN2P3-CC_MCDISK. with
Source Host [dcsrm.usatlas.bnl.gov].
now that T0-LYON transfers are also on production dashb, such errors are not nice in monitoring the ccrc transfers. GGUS-Ticket 36755 has been created.
- 23 May 08h20
Beijing has started working since 01:44, although with a number of errors until 07:43.
[FTS] FTS State [Failed] FTS Retries [1] Reason [TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out] Source Host [ccsrm.in2p3.fr]
after the last error at 07:43, transfers seem going well.
RO-02-NIPNE_DATADISK also working from time to time. still with many errors
Thu, 22 May
- Throughput (MB/s) within LYON cloud (T0-LYON + LYON-T2s) during the day 22 May
- Number of errors within LYON cloud (T0-LYON + LYON-T2s) during the day 22 May


- There was a network problem for Romanian national Internet provider RoEdu from 6:30 to 10 GMT, according to Titi and Mihai.
- 22 May 22h50
Transfers to RO-02-NIPNE_DATADISK have been failing. GGUS-Ticket 36728 has been created.
Otherwise, transfers are going well except for BEIJING.
- 22 May 14h50
One file assigned to CPPM has a source problem;
Received error message: SOURCE error during PREPARATION phase: [REQUEST_TIMEOUT] failed to prepare source file in 180 seconds
with srm://marsedpm.in2p3.fr:8446/srm/managerv2?SFN=/dpm/in2p3.fr/home/atlas/atlasdatadisk/ccrc08_run2/AOD/ccrc08_run2.016765.physics_C.merge.AOD.o0_r0_t0/ccrc08_run2.016765.physics_C.merge.AOD.o0_r0_t0._0001__DQ2-1211460721
GGUS-Ticket 36709 has been created. https://gus.fzk.de/pages/ticket_details.php?ticket=36709
- 22 May 14h20
the T0->LYON export was migrated from T0 VOBOX to LYON VOBOX. Transfers T0->LYON should be monitored with the Production dashboard http://dashb-atlas-data.cern.ch/dashboard/request.py/site?name=LYON
- 22 May 13h05
Titi: Unfortunately there was an unscheduled network breakdown in our institute started from about 6:30 to 10 GMT.
- 22 May 12h40
Stephane switched back the certificate from Kors' certificate to Mario's.
Then again seeing problems, went again with Kors'.
- 22 May 10h29
starting 09:21:35, there are errors in transfers to RO-07-NIPNE_DATADISK in dashb.
[FTS] FTS State [Failed] FTS Retries [1] Reason [DESTINATION error during PREPARATION phase: [CONNECTION] failed to contact on remote SRM [httpg://tbit00.nipne.ro:8446/srm/managerv2]. Givin' up after 3 tries] Source Host [ccsrm.in2p3.fr]
GGUS-Ticket 36698 created
24 May 2008 11:35, Mihai: Sorry for this problem.But this was happening because of a problem occurred to our national Internet provider RoEdu.
- 22 May 09h40
According to Alexei, cron job for subscription to T2s does not run frequently during the night. That is why.
- 22 May 09h00
transfers T1-T2 resumed since 8h30. reaching 900MB/s in total.
numbers of assigned datasets to sites look better now.
Killed a MC data subscription to RO-07-NIPNE_MCDISK.
- 22 May 08h00
T0-T1 transfers are proceeding, No T1-T2 transfers to DATADISK since last night.
according to dq2.log, new subscriptions today (since 5.22 00:00) are queued only to BEIJING and RO-02-NIPNE, resulting in errors.
the status table does not look nice, I will check. http://panda.atlascomp.org/?mode=listFunctionalTests&testType=T1toT2s#LYON
apparently, no subscription to LAPP, CPPM, LPSC. TOKYO and LAL, who are assigned larger shares, have less subscriptions.
21 May
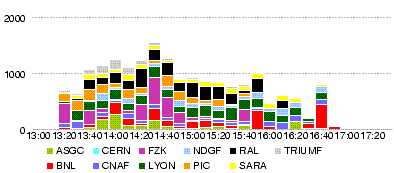
Attention! dashb shows wrong results http://dashb-atlas-data.cern.ch/dashboard/request.py/site?name=LYON&fromDate=2008-05-21%2000:00&toDate=2008-05-22%2000:00
And the graphs can also be wrong
- Throughput (MB/s) all T0-T1 during the day 21 May
- Throughtput (MB/s) T0-LYON during the day 21 May
- Throughput (MB/s) LYON-T2 during the day 21 May



- 21 May 23h30
There are many errors in transfers to NIPNE02
DESTINATION error during PREPARATION phase: [PERMISSION]
- 21 May 22h30
Stephane found a temporary solution for the LFC problem. It does not accept Mario's certificate, but does Kors' (thus no problem in T0-T1 transfers).
- 1 file ccrc08_run2.016730.physics_E.merge.AOD.o0_r0_t0._0001 to BEIJING done. http://dashb-atlas-data.cern.ch/dashboard/request.py/file-placement?site=BEIJING-LCG2_DATADISK&guid=45e816b9-82aa-434c-99f7-eb2ff3f7f9c9
- 9 datasets transferred to LPNHE http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=GRIF-LPNHE_DATADISK
- 9 datasets transferred to Saclay http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=GRIF-SACLAY_DATADISK
- no transfers to CPPM
- no transfers to LAPP
- 1 dataset ccrc08_run2.016733.physics_E.merge.AOD.o0_r0_t0 completed to LPC http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=IN2P3-LPC_DATADISK
- 2 datasets to RO-02-NIPNE_DATADISK in queue http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=RO-02-NIPNE_DATADISK
- 6 datasets to RO-07-NIPNE_DATADISK completed http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=RO-07-NIPNE_DATADISK
- no transfer to Tokyo after the very first one http://dashb-atlas-data.cern.ch/dashboard/request.py/dataset?site=TOKYO-LCG2_DATADISK
the dashb graphs show these transfers as of 19:xx (transfers done at 19:xx = 17:xx UTC, and registration done at around 22:30)
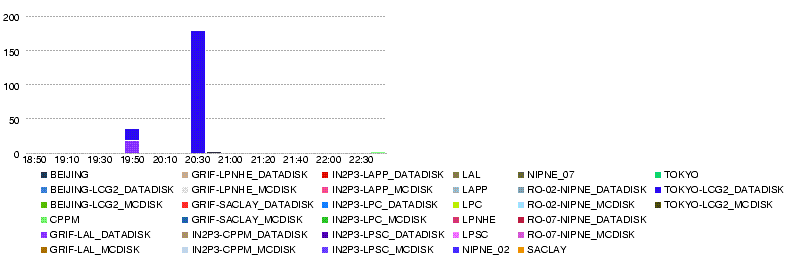
- 21 May 20h20
dashb shows transfers, which seem to be successful but with many registration errors, in the table (not in the graph). Looking into the details, file states are 'ATTEMPT_DONE' with 'HOLD_FAILED_REGISTRATION'. Errors in registration do not seem to appear on the error graph which is for transfer errors.
- Throughput LYON-T2 (MB/s)


- 1 file ccrc08_run2.016730.physics_E.merge.AOD.o0_r0_t0._0001 has been transferred to BEIJING at 17:40:07 (submit time 17:34:04), all the other transfers failed with
globus_gass_copy_register_url_to_url: Connection timed out
http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=1beaf3f7-275c-11dd-a6af-d4b2876399e2 - 15 files transferred to IRFU at 17:35-17:46 (submit time 17:34:59) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=3c5f360b-275c-11dd-a6af-d4b2876399e2
- 2 files transferred to IRFU at 17:33 (submit time 17:32:56) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=f2d33d11-275b-11dd-a6af-d4b2876399e2
- 1 file ccrc08_run2.016733.physics_E.merge.AOD.o0_r0_t0._0001 has been transferred to IN2P3-LPC at 17:33 (submit time 17:32) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=f41f6c22-275b-11dd-a6af-d4b2876399e2
- 2 files transferred to IN2P3-LPNHE at 17:33 (submit time 17:32) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=f28bfae0-275b-11dd-a6af-d4b2876399e2
- 17 files transferred to IN2P3-LPNHE at 17:35-17:41 (submit time 17:34)
- all transfers to RO-02-NIPNE ATLASDATADISK are failing
TRANSFER error during TRANSFER phase: [PERMISSION] the server sent an error response: 550 550 rfio write failure: Permission denied.
TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out
TRANSFER error during TRANSFER phase: [GRIDFTP] the server sent an error response: 426 426 Transfer aborted (Unexpected Exception : java.io.IOException: Broken pipe)
DESTINATION error during PREPARATION phase: [PERMISSION]
http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftschannel.php?channel=IN2P3-NIPNE02&vo=atlas - 10 files transferred to NIPNE07 at 17:44-18:02 (submit time 17:35) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=53b15d6f-275c-11dd-a6af-d4b2876399e2
- 2 files transferred to NIPNE07 at 17:33 (submit time 17:33) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=0bb83976-275c-11dd-a6af-d4b2876399e2
- 3 files transferred to TOKYO at 13:00 (submit time 13:00) http://cctoolsafs.in2p3.fr/fts/monitoring/prod/ftsjob.php?jobid=eae79bb0-2735-11dd-a6af-d4b2876399e2
the time on ftsmonitor is UTC.
- 21 May 19h30
Finally 19 more subscriptions appeared in the dq2.log.
- ccrc08_run2.016731.physics_D.merge.AOD.o0_r0_t0 (2 files) to BEIJING-LCG2_DATADISK and GRIF-SACLAY_DATADISK
- ccrc08_run2.016730.physics_B.merge.AOD.o0_r0_t0 (2 files) to BEIJING-LCG2_DATADISK and GRIF-SACLAY_DATADISK
- ccrc08_run2.016730.physics_D.merge.AOD.o0_r0_t0 (2 files) to BEIJING-LCG2_DATADISK and GRIF-SACLAY_DATADISK
and so on.
In the dq2.log, the files got FileTransferring, VALIDATED, FileCopied, but then, there are errors
FileTransferErrorMessage : reason = [FTS] FTS State [Failed] FTS Retries [1] Reason [TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_gass_copy_register_url_to_url: Connection timed out] FileRegisterErrorMessage : reason = LFC exception [Cannot connect to LFC [lfc://lfc-prod.in2p3.fr:/grid/atlas]]
- 21 May 18h20
Around 17h30 transfers resumed. Rate for 17h40-18h20: IN2P3-CC_DATADISK: 158 MB/s, IN2P3-CC_DATATAPE: 37 MB/s
no subscriptions/transfers T1-T2 since the very first dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 (vuid = 6403bd5a-5a71-4732-9a0a-b22b56aef106) to GRIF-LAL_DATADISK and TOKYO-LCG2_DATADISK. Transfers to Tokyo has finished. LAL is still Inactive.
21 May 16h40
Since around 16:40 T0-T1 transfers stopped. There are many errors.
SOURCE error during PREPARATION phase: [GENERAL_FAILURE] Error caught in srm::getSrmUser.Error creating statement, Oracle code: 12537ORA-12537: TNS:connection closed] Source Host [srm-atlas.cern.ch]
- Overall throughput T0-T1s 21 May 13h - 17h
- Overall number of errors T0-T1s 21 May 13h - 17h

- Overall throughput T0-Lyon 21 May 13h - 17h
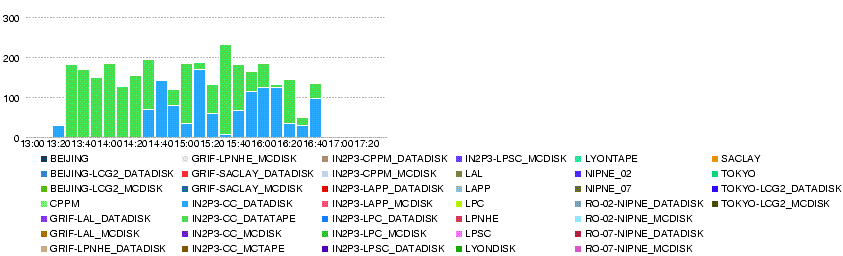
- Overall number of errors T0-Lyon 21 May 13h - 17h
- Overall throughput T0-T1s 21 May 13h - 17h




21 May 13h30
T0-T1 Transfers started at around 13h30.
The overall throughput from T0 is over 1000MB/s.
Lyon is receiving its share at 100-200 MB/s (verying with time).
the average rate is about 40MB/s to IN2P3-CC_DATADISK
and 140MB/s to IN2P3-CC_DATATAPE according to dashb http://dashb-atlas-data-tier0.cern.ch/dashboard/request.py/site?name=LYON.
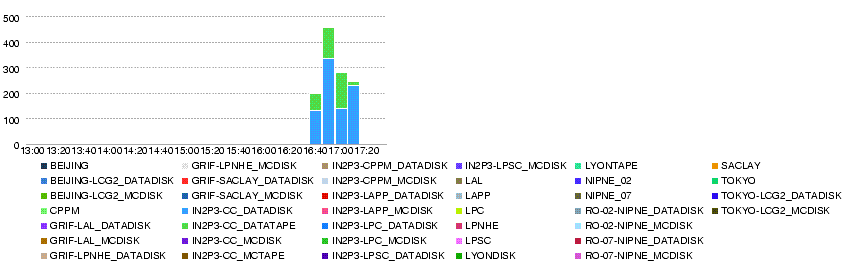
- Overall throughput T0-T1s in 4h up to 15h30 21 May
- Throughput T0-Lyon in 4h up to 15h30 21 May


T1-T2 Transfers started at around 15h10. http://lcg2.in2p3.fr/wiki/images/20080521-1530-LYONT2.throughput.14400.png
- from dq2.log:
- 2008-05-21 15:00: SubscriptionQueued for dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 (vuid = 6403bd5a-5a71-4732-9a0a-b22b56aef106) to GRIF-LAL_DATADISK and TOKYO-LCG2_DATADISK
- 2008-05-21 15:00: FileTransferring: 3 files of the dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 (fsize = 3600000000 each) for both TOKYO-LCG2_DATADISK and GRIF-LAL_DATADISK
- 2008-05-21 15:03: VALIDATED: 3 files of dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 at srm://lcg-se01.icepp.jp
- 2008-05-21 15:03: FileCopied: 3 files of dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 at TOKYO-LCG2_DATADISK
- 2008-05-21 15:03: FileDone: 3 files of dataset ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 at TOKYO-LCG2_DATADISK
- 2008-05-21 15:05: SubscriptionComplete: vuid = 6403bd5a-5a71-4732-9a0a-b22b56aef106 : site = TOKYO-LCG2_DATADISK : dsn = ccrc08_run2.016731.physics_A.merge.AOD.o0_r0_t0 : version = 1
- FTS channels for LAL are 'Inactive' for 'Pb clim LAL'
Extra tests
GRIF (26 May)
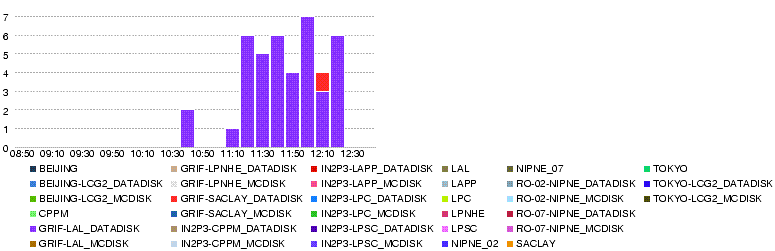
- 26 May 12h50
- Througput (MB/s)
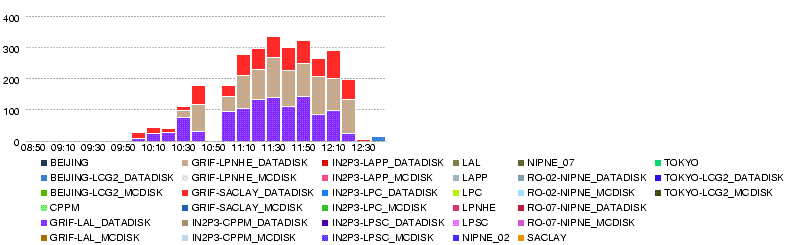
- Errors


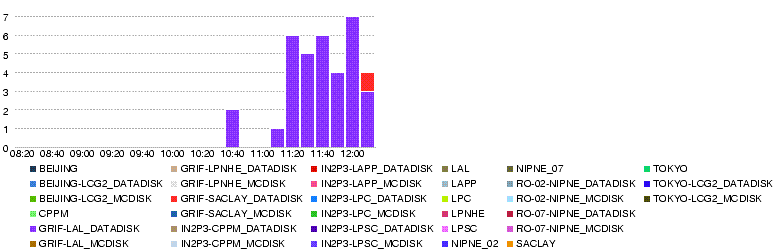
- 26 May 12h14
- Througput (MB/s)
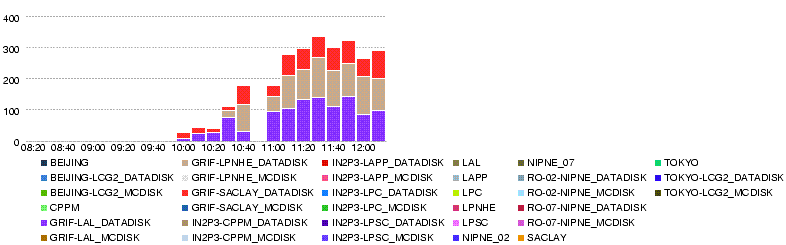
- Errors


BEIJING (26 May)
- 27 May 14h15
Erming:
I tuned the IN2P3-BEIJING channel to 20 concurrent files and 5 concurrent streams. I tested many combinations: Nofiles NoStreams 5 3 10 5 15 5 20 5 20 10 25 5 30 5 It appears that 20/5 is the best for the moment which can reach more than 80MB/s throughput.
- 26 May
Number of concurrent files increased, and tested.
- Throughput (MB/s)
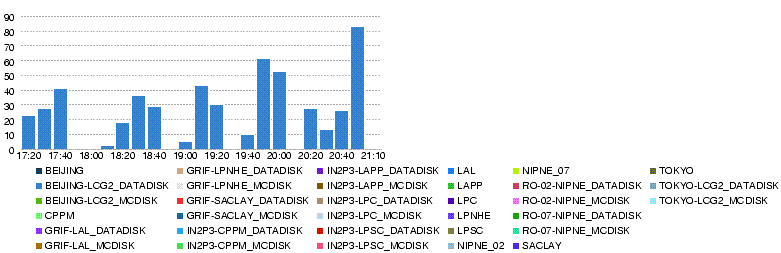
- Errors


T0-T1-T2 + T1-T1 transfer + MC production (week4)
Plan
ADC Oper 22 May (slide 8 - 10) http://indico.cern.ch/materialDisplay.py?contribId=3&materialId=slides&confId=34556
Friday morning: data generation stops
- T0-T1-T2
- Datasets named ccrc08_run2.018* produced at the nominal rate
- T1-T1
- Datasets named ccrc08_run2.017* (ESD+AOD only, no RAW) produced at the nominal rate (up to 29 May in the morning).
- The ESDs are replicated only between the paired T1s during the first two days. AODs are replicated to everywhere.
- Datasets named ccrc08_run2.019* (ESD+AOD only, no RAW) produced at the nominal rate (since 29 May in the morning)
- The ESDs are replicated from every T1 to every other T1s for the last two days.
nominal rate = 200Hz * 14h/day = 10 M events/day
RAW: 1.6 MB/event, nominal 16TB/day
ESD: 1.0 MB/event, nominal 10TB/day
AOD: 0.1 MB/event, nominal 1TB/day
LYON T1
RAW: in from T0: 15% nominal = 2.4TB/day
ESD: in from T0: 15%+15% nominal = 3TB/day
in from partner T1 (60% of BNL): 15% nominal = 1.5TB/day (at first)
in from all other T1: 85% nominal = 8.5TB/day (later)
out to partner T1: 15% nominal = 1.5TB/day (at first)
out to all other T1: 9*15% nominal = 13.5TB/day (later)
AOD: in from T0: 100%+15% nominal = 1.15TB/day
in from other T1s: 85% nominal = 0.85TB/day
out to all other T1s: 9 * 15% nominal = 1.35TB/day
out to T2s: 100% nominal * sum(T2 shares) = 1TB*sum(T2shares)/day
total in: 2.4TB/day on tape, 28MB/s, 9.6TB/4d
in: 6.5TB/day on disk, 75MB/s, 26TB/4d (first)
in: 13.5TB/day on disk, 156MB/s (later)
out to T1s 2.85TB/day, 33MB/s (first)
out to T1s 15TB/day, 172MB/s (later)
out to T2s 1*sum(T2 shares) TB/day, 12*sum(T2 shares) MB/s
- subscription cron
Datasets are subscribed to T1s from partner Tier-1s ~ every 2h
Datasets are subscribed to T2s from parent Tier-1s ~ every 4h
T0 - T1
- Monitor page: http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T0toT1s
T1 - T2
- Monitor page: http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT2s
- Shares requested for the T2s, and data volume estimation done by I.Ueda
* IN2P3-LAPP_DATADISK : 25% 0.25TB/d, 2.9MB/s, 1.0TB/4d
* IN2P3-CPPM_DATADISK : 5% 0.05TB/d, 0.6MB/s, 0.2TB/4d
* IN2P3-LPSC_DATADISK : 5% 0.05TB/d, 0.6MB/s, 0.2TB/4d
* IN2P3-LPC_DATADISK : 25% 0.25TB/d, 2.9MB/s, 1.0TB/4d
* BEIJING-LCG2_DATADISK : 20% 0.20TB/d, 2.3MB/s, 0.8TB/4d
* RO-07-NIPNE_DATADISK : 10% 0.10TB/d, 1.2MB/s, 0.4TB/4d
* RO-02-NIPNE_DATADISK : 10% 0.10TB/d, 1.2MB/s, 0.4TB/4d
* GRIF-LAL_DATADISK : 45% 0.45TB/d, 5.2MB/s, 1.8TB/4d
* GRIF-LPNHE_DATADISK : 25% 0.25TB/d, 2.9MB/s, 1.0TB/4d
* GRIF-SACLAY_DATADISK : 30% 0.30TB/d, 3.5MB/s, 1.2TB/4d
* TOKYO-LCG2_DATADISK : 100% 1.0 TB/d, 11.6MB/s, 4.0TB/4d
------------------------------------------------------------------
Total : 300% 3.0 TB/d, 34.7MB/s, 12.0TB/4d
- Tue, 27 May 2008 17:17:29 +0200, From: Alexei Klimentov
- subscriptions from T1 to parent T2s are done every 3-4h - local file catalogs are checked every 2h http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT2s There were several requests to change '%%' I attach the last table I am using (there are 48 T2s participating) line INFN-FRASCATI_DATADISK | 25 | INFN-MILANO_DATADISK means that INFN-FRASCATI_DATADISK will be subscribed to 25% of AODs from CNAF and datasets@FRASCATI shouldn't overlap with the datasets@MILANO Subscriptions are done using my certificate
- Alexei's table for T2s
GRIF-LAL_DATADISK 45 GRIF-LPNHE_DATADISK,GRIF-SACLAY_DATADISK GRIF-LPNHE_DATADISK 25 GRIF-SACLAY_DATADISK,GRIF-LAL_DATADISK GRIF-SACLAY_DATADISK 30 GRIF-LPNHE_DATADISK,GRIF-LAL_DATADISK IN2P3-CPPM_DATADISK 5 IN2P3-LAPP_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK IN2P3-LAPP_DATADISK 25 IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK IN2P3-LPC_DATADISK 25 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK IN2P3-LPSC_DATADISK 5 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPC_DATADISK,BEIJING-LCG2_DATADISK,RO-02-NIPNE_DATADISK,RO-07-NIPNE_DATADISK RO-02-NIPNE_DATADISK 10 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING_DATADISK,RO-07-NIPNE_DATADISK RO-07-NIPNE_DATADISK 10 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK,IN2P3-LPC_DATADISK,BEIJING_DATADISK,RO-02-NIPNE_DATADISK TOKYO-LCG2_DATADISK 100 IN2P3-LAPP_DATADISK,IN2P3-CPPM_DATADISK,IN2P3-LPSC_DATADISK
T1 - T1
- Date: Tue, 27 May 2008 17:17:29 +0200, From: Alexei Klimentov
- subscriptions are done every 2h - local file catalogs are checked every hour http://pandamon.usatlas.bnl.gov:25880/server/pandamon/query?mode=listFunctionalTests&testType=T1toT1s ESD subscriptions BNL : all ccrc08_run2.0170*ESD* datasets Other sites : line | FZK-LCG2_DATADISK | 40 | BNL-OSG2_DATADISK | means FZK is subscribed to 40% of ccrc08_run2.0170*ESD* from BNL (important, 40% calculated from the number of completed datasets at BNL) 40% at FZK and 60% at LYON shouldn't overlap (ditto, for INFN and NIKHEF) subscription is done with '--source' and w/o '--wait-for-source' options subscriptions are done using Kors cert +------------------------+------------+------------------------+ | tier1 | percentage | tier1_pair | +------------------------+------------+------------------------+ | FZK-LCG2_DATADISK | 40 | BNL-OSG2_DATADISK | | IN2P3-CC_DATADISK | 60 | BNL-OSG2_DATADISK | | INFN-T1_DATADISK | 50 | RAL-LCG2_DATADISK | | NDGF-T1_DATADISK | 100 | PIC_DATADISK | | NIKHEF-ELPROD_DATADISK | 50 | RAL-LCG2_DATADISK | | PIC_DATADISK | 100 | NDGF-T1_DATADISK | | RAL-LCG2_DATADISK | 100 | INFN-T1_DATADISK | | RAL-LCG2_DATADISK | 100 | NIKHEF-ELPROD_DATADISK | | TAIWAN-LCG2_DATADISK | 100 | TRIUMF-LCG2_DATADISK | | TRIUMF-LCG2_DATADISK | 100 | TAIWAN-LCG2_DATADISK | +------------------------+------------+------------------------+
Logbook
Fri, 30 May
- 30 May 14h33
- CERN-IN2P3 link intervention
Subject: [CERN-LHCOPN] Emergency maintenance NOW - CERN-IN2P3 link affected
Following the power incident this morning we have detected a problem on the router module that connect to IN2P3. We need to immediately intervene on it. DATE AND TIME: Friday 30th of June 14:20 to 15:00 CEST IMPACT: The link LHCOPN CERN-IN2P3 will flap several time. Traffic to IN2P3 will be rerouted to the backup path.
- 30 May 11h05
- dashb-t0 has also been back.
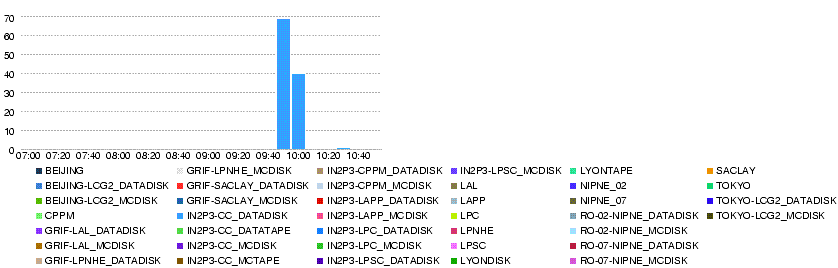
- T0-T1s Throughput (MB/s)
- T0-LYON Throughput (MB/s)
- T0-LYON Number of files
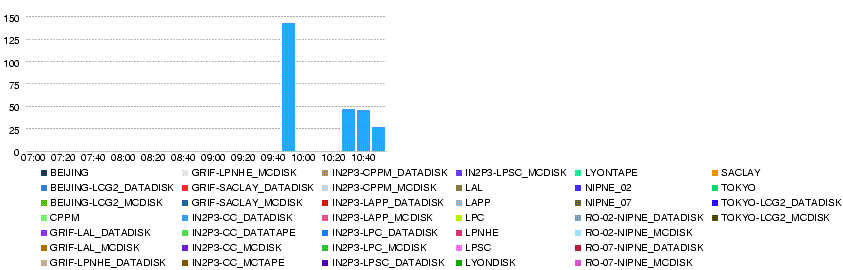
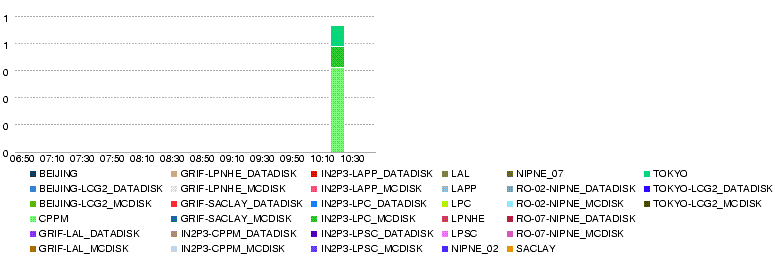
- T0-LYON Number of errors
- LYON-T2s Throughput (MB/s)
- LYON-T2s Number of files
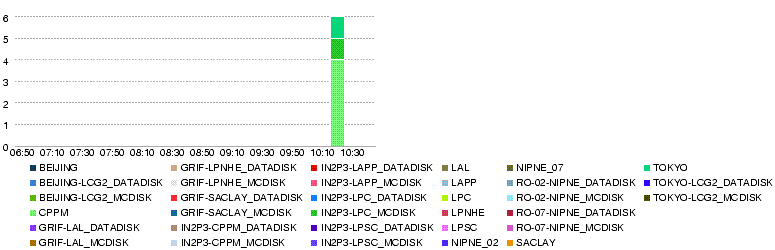
- 'LYON-T2s Number of errors
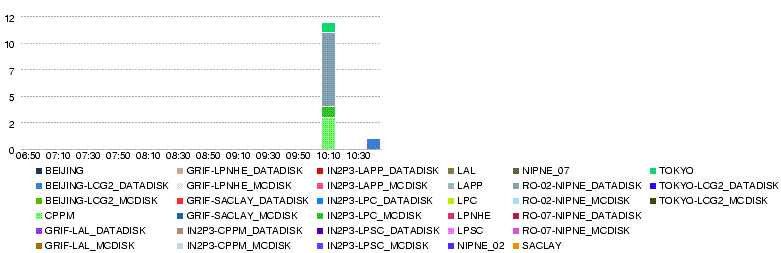







- 30 May 10h35
- dashb-prod is back
- 30 May 9h00
- The plan was to stop the data generation at T0 during the morning, but there was a CERN wide powercut (see http://cern.ch/ssb), so this was the end of the generation. We just wait and see all the subscriptions to be processed and replication to be completed.
- A snapshot will be taken at noon tomorrow - subscriptions and monitoring by Alexei will be stopped - and then all the ccrc08_run2 data will be deleted.
- dashb monitors are still down - dashb-prod shows the graphs only up to 04:50, dashb-t0 still not accessible.
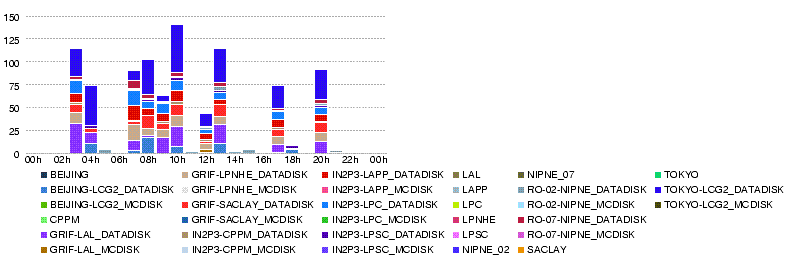
Thu, 29 May
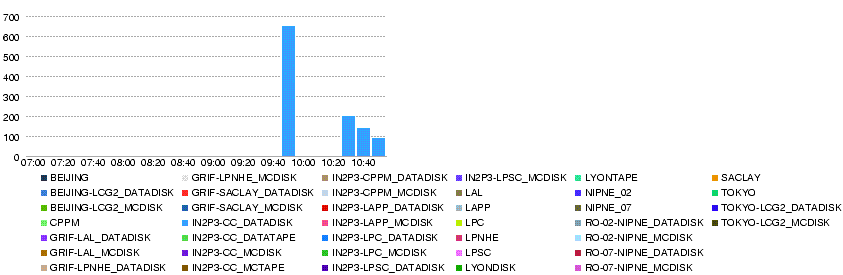
- Snapshot of the replication monitor page
- at 05.30 00:05 (cannot tell the cache time -- the numbers as of what time)
[[Image:Atlas-ListT1T2-20080530-0005. - T0-Lyon Throughput (MB/s) during the day 29 May
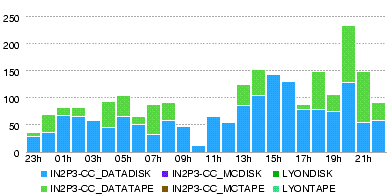
- T0-Lyon Number of files during the day 29 May
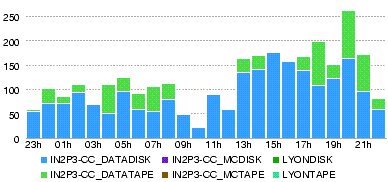
- T0-Lyon Errors
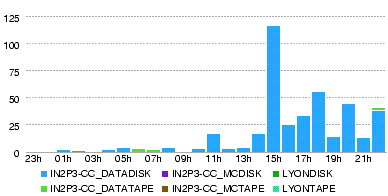
- Lyon-T2 Throughput (MB/s) during the day 29 May
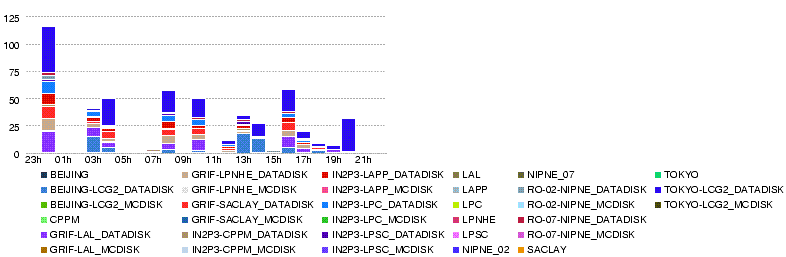
- Data volume transferred (GB) during the day 29 May
- Number of files transferred during the day 29 May
- Number of errors in transfers during the day 29 May








- 29 May 13h10
- The pandamon page for the T1-T2 replication (cached on Thu, 29 May 2008 09:46:09) showed the following numbers:
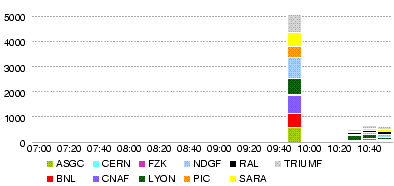
BNL AGLT2_DATADISK 275 MWT2_DATADISK 275 NET2_DATADISK 275 SLACXRD_DATADISK 275 SWT2_CPB_DATADISK 275 CNAF INFN-NAPOLI-ATLAS_DATADISK 275 INFN-ROMA1_DATADISK 275 LYON BEIJING-LCG2_DATADISK 66 GRIF-LAL_DATADISK 113 GRIF-LPNHE_DATADISK 68 GRIF-SACLAY_DATADISK 79 IN2P3-CPPM_DATADISK 14 IN2P3-LAPP_DATADISK 68 IN2P3-LPC_DATADISK 71 IN2P3-LPSC_DATADISK 14 RO-02-NIPNE_DATADISK 29 RO-07-NIPNE_DATADISK 28 TOKYO-LCG2_DATADISK 254
- at 11h50, dq2-list-dataset-site tells IN2P3-CC_DATADISK has 258 'ccrc08_run2.018.*AOD' datasets, while INFN-T1_DATADISK has 275 and BNL also.
IN2P3-CC_DATADISK 258 INFN-T1_DATADISK 275 TOKYO-LCG2_DATADISK 253 INFN-NAPOLI-ATLAS_DATADISK 275 INFN-ROMA1_DATADISK 275
- Tokyo (254 in the table = assigned, and 253 by dq2 = exist) seems ok, for not all the 258 datasets at Lyon are complete.
- GRIF (113+68+79=260 in the table, 259 by dq2)...?
- Others (290 in the table, 281 by dq2)... too many
IN2P3-LAPP_DATADISK 68 IN2P3-CPPM_DATADISK 14 IN2P3-LPSC_DATADISK 14 IN2P3-LPC_DATADISK 71 BEIJING-LCG2_DATADISK 59 RO-07-NIPNE_DATADISK 28 RO-02-NIPNE_DATADISK 27 total 281
- checking with dq2-list-dataset-site, all the datasets in RO-07-NIPNE_DATADISK are also found in BEIJING-LCG2_DATADISK.
- 29 May 9h30
- http://cern.ch/ssb ATLAS Castor SRM service intervention between 9:00 and 10:00 am The ATLAS Castor SRM service will be down for one hour to move the backend database to more powerful hardware. There will be no WAN transfers for ATLAS during this period. The rest of Castor ATLAS will not be affected.
- 29 May 9h30
- load generator for T1-T1 datasets has switched from run 017 to run 019.
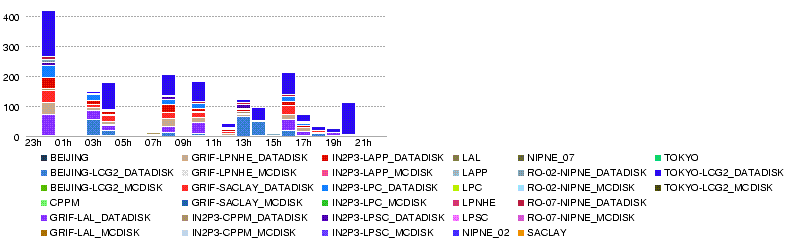
- Throughput (MB/s) during 4h up to 29 May 23h05
- Throughput (MB/s) during 4h up to 29 May 19h05
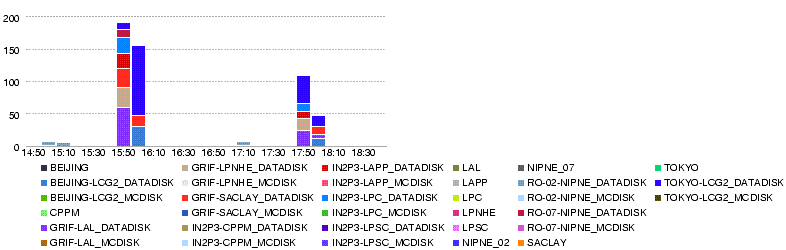
- Throughput (MB/s) during 4h up to 29 May 15h00
- Throughput (MB/s) during 4h up to 29 May 11h00
- Throughput (MB/s) during 4h up to 29 May 07h00

- Throughput (MB/s) during 4h up to 29 May 03h00







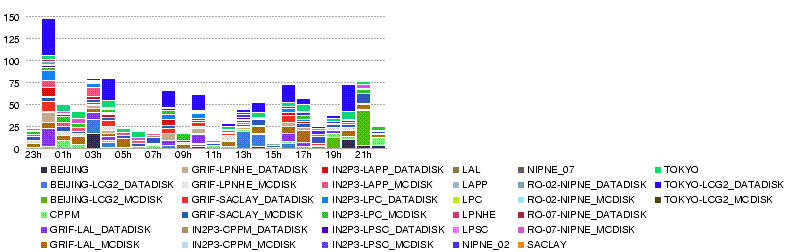
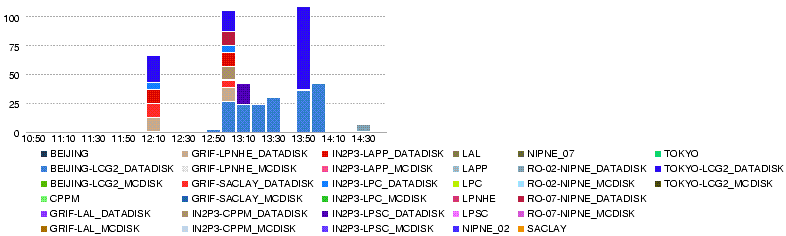
Wed, 28 May
- Throughput (MB/s) during the day 28 May
- Data volume transferred (GB) during the day 28 May
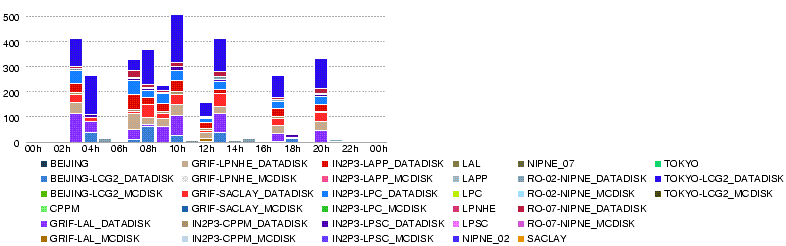
- Number of files transferred during the day 28 May
- Number of errors in transfers during the day 28 May




- 28 May 13h00
- Being bothered by MC transfer errors with 'file not found' at the source sites (BNLPANDA, NDGFT1DISK), sent Savannah bug items 37054, 37055
- 28 May 11h15
- Erros in the last 24h;
Transfers Site Eff. Succ. Errors BEIJING-LCG2_DATADISK 75% 134 45 GRIF-LAL_DATADISK 94% 150 10 GRIF-LPNHE_DATADISK 99% 99 1 GRIF-SACLAY_DATADISK 100% 100 0 IN2P3-CPPM_DATADISK 100% 18 0 IN2P3-LAPP_DATADISK 99% 95 1 IN2P3-LPC_DATADISK 100% 101 0 IN2P3-LPSC_DATADISK 100% 22 0 RO-02-NIPNE_DATADISK 34% 28 55 RO-07-NIPNE_DATADISK 100% 38 0 TOKYO-LCG2_DATADISK 98% 319 7
| [TRANSFER error during TRANSFER phase: [GRIDFTP] the server sent an error response: 426 426 Transfer aborted (Unexpected Exception : java.io.IOException: Broken pipe)] | [TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out] | [TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_gass_copy_register_url_to_url: Connection timed out] | [SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out] | [TRANSFER error during TRANSFER phase: [GRIDFTP] an end-of-file was reached (possibly the destination disk is full)] | [TRANSFER error during TRANSFER phase: [PERMISSION] the server sent an error response: 550 550 rfio write failure: Permission denied.] | |
| BEIJING-LCG2_DATADISK | 15 | 14 | 14 | 1 | 1 | |
| GRIF-LAL_DATADISK | 2 | 7 | 4 | |||
| GRIF-LPNHE_DATADISK | 1 | |||||
| IN2P3-LAPP_DATADISK | 1 | |||||
| RO-02-NIPNE_DATADISK | 2 | 48 | 1 | 4 | ||
| TOKYO-LCG2_DATADISK | 4 | 3 |
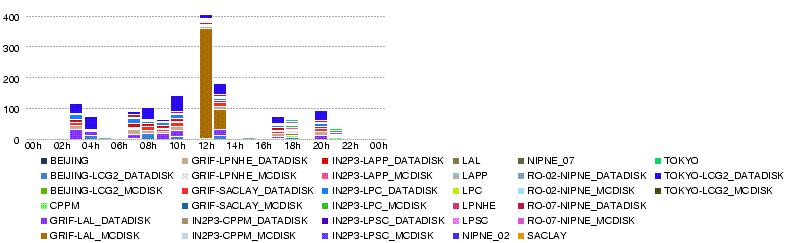
- 28 May 09h00
- Transfers to T2s are going well.

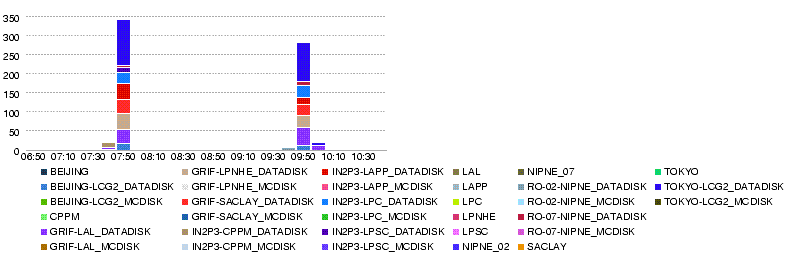
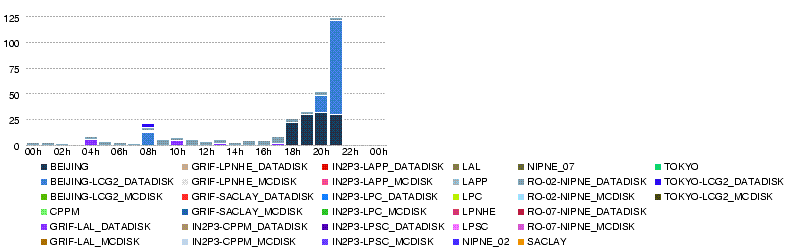
Tue, 27 May
- Throughput (MB/s) during the day 27 May
- Volume transferred (GB) during the day 27 May
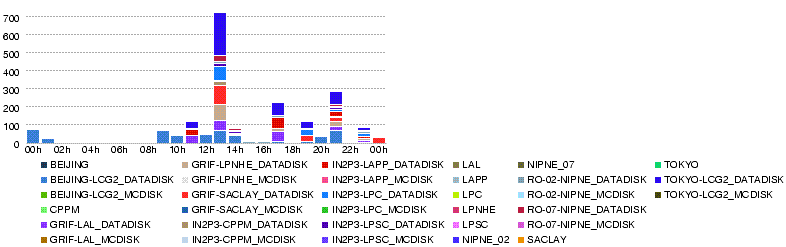
- Number of files transferred during the day 27 May
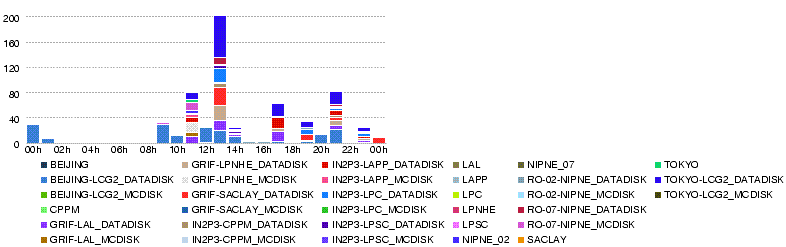
- Number of errors in transfers during the day 27 May
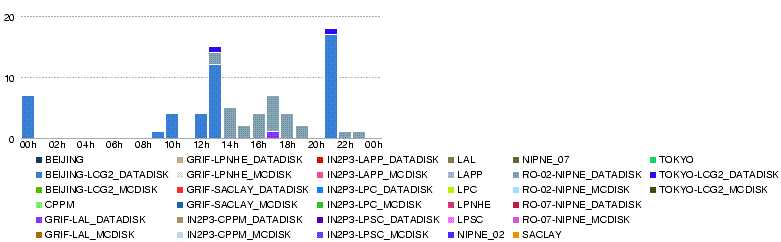




- 27 May 16h40
- some more info about errors.
- BEIJING has had 11
[TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_gass_copy_register_url_to_url: Connection timed out]
- RO-02-NIPNE had 7
[TRANSFER error during TRANSFER phase: [TRANSFER_TIMEOUT] gridftp_copy_wait: Connection timed out]
- and 1
[SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out]
- TOKYO-LCG2: 1
[SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out]
- Number of Files Transferred

- Errors


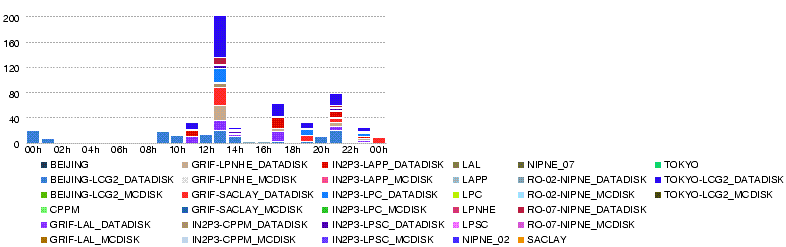
- 27 May 14h00
- We reached nearly 700MB/s in total
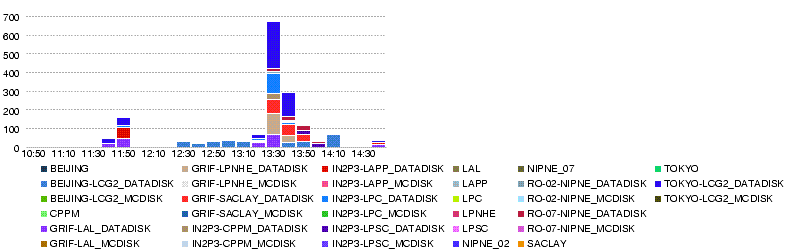
- with only small number of errors
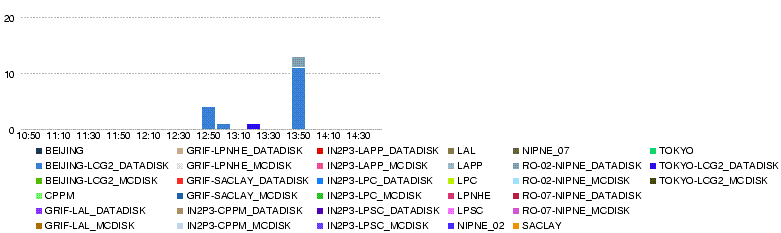


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
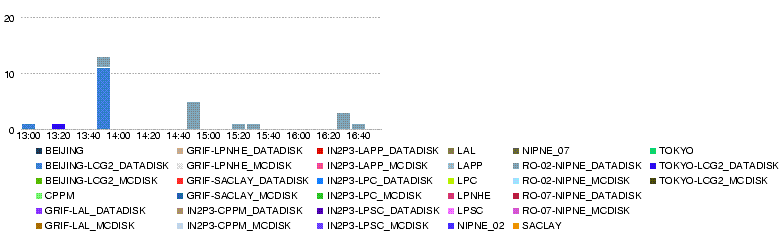
- 27 May 11h40
- The T1-T2 transfers have started
- 27 May 09h50
- The T0 data generation has started already yesterday.
The T0 export is being started. (That is, there is a large backlog for T0-T1.)
Mon, 26 May
- 26 May 20h00
- Still don't see any ccrc08_run2 datasets being transferred. (the activities for T0-T1 are data08_cosm7).
- 26 May 18h50
- around 18h50 T0-LYON transfers went back to T0 vobox, monitored by T0 dashb.
- 26 May 15h40
- cosmic data transfers ongoing (data08_cosm7, T0-T1) need to wait still more before ccrc data to come out.