Difference between revisions of "User talk:LEROY"
(→2)un des plugin ('/opt/lcg/libexec/lcg-info-dynamic-maui') est buggé) |
|||
| (4 intermediate revisions by the same user not shown) | |||
| Ligne 1: | Ligne 1: | ||
= Mise hors service du LCG-CE (réinstallé en serveur (Maui + torque Only)) = | = Mise hors service du LCG-CE (réinstallé en serveur (Maui + torque Only)) = | ||
| + | Mise hors service du LCG-CE via Quattor sur un cluster avec : | ||
| + | -une machine, M1 :(lcg-CE +Maui + torque) et | ||
| + | |||
| + | - une deuxième Machine, M2 : CREAM-CE | ||
| + | |||
| + | La Première machine étant réinstallé en serveur (Maui + torque Only) | ||
| + | |||
| + | |||
| + | |||
| + | == 1)M1 : serveur Maui + torque Only en SL5 == | ||
| + | === a)Inclure un nouveau type de machine dans M1 === | ||
| + | |||
| + | include { 'machine-types/torque_server' (a la place du glite_ce) | ||
| + | |||
| + | === b)Ajouter la derniere version de maui === | ||
| + | '/software/packages'=pkg_repl('maui','3.3.1-1.sl5','x86_64'); | ||
| + | '/software/packages'=pkg_repl('maui-client','3.3.1-1.sl5','x86_64'); | ||
| + | '/software/packages'=pkg_repl('maui-server','3.3.1-1.sl5','x86_64'); | ||
| + | |||
| + | === c) SL5 === | ||
| + | |||
| + | Deplacer le profile ainsi que le template 'pro_lcg2_config_site_maui.tpl' dans le '''cluster glite 3.2''' et modifier le '*nodes_properties.tpl' (install SL5) | ||
| + | |||
| + | === d) Declarer une nouvelle variable === | ||
| + | variable '''LRMS_SERVER_HOST''' dans 'pro_lcg2_config_site.tpl' et 'pro_site_common_config.tpl' | ||
| + | |||
| + | |||
| + | |||
| + | Template modifié lors de ces étapes: | ||
| + | |||
| + | Suppression cfg/clusters/irfu/glite-3.1/profiles/profile_node07.tpl | ||
| + | Suppression cfg/clusters/irfu/glite-3.1/site/pro_lcg2_config_site_maui.tpl | ||
| + | Ajout cfg/clusters/irfu/glite-3.2/profiles/profile_node07.tpl | ||
| + | Ajout cfg/clusters/irfu/glite-3.2/site/pro_lcg2_config_site_maui.tpl | ||
| + | Envoi cfg/sites/dapnia/site/config/dapnia_nodes_properties.tpl | ||
| + | M cfg/clusters/irfu/test-glite-3.2/site/pro_lcg2_config_site.tpl | ||
| + | M cfg/clusters/irfu/glite-3.1_MPI/profiles/profile_node16.tpl | ||
| + | M cfg/clusters/irfu/glite-3.1_MPI/site/pro_lcg2_config_site.tpl | ||
| + | M cfg/clusters/irfu/glite-3.2_MPI/site/pro_lcg2_config_site.tpl | ||
| + | M cfg/sites/dapnia/site/pro_site_common_config.tpl | ||
| + | M cfg/sites/dapnia/site/pro_site_ui_dapnia_users_env.tpl | ||
| + | M cfg/sites/dapnia/site/pro_lcg2_config_site.tpl | ||
| + | |||
| + | == 2) Déplacer le site BDII sur une autre machine (anciennement sur M1 (le LCG-CE)) == | ||
| + | |||
| + | Enlever les variable de configuration de BDII sur M1 et les ajouter sur une autre machine (LFC exemple) : | ||
| + | variable BDII_TYPE='site'; # site bdii | ||
| + | variable BDII_SUBSITE_ONLY = false; | ||
| + | variable BDII_SUBSITE = 'IRFU'; | ||
| + | |||
| + | == 3) Résoudre l’erreur : Bad UID for job execution == | ||
| + | http://grid.pd.infn.it/cream/field.php?n=Main.ErrorMessagesReportedByCREAMToClient#badui | ||
| + | en rajoutant le fichier mentionné: /etc/hosts.equiv | ||
| + | |||
| + | == 4) Resoudre le probleme de ‘resource not available’ vu par les WMS : == | ||
| + | |||
| + | En fait le système d’information ne marchait pas bien sur M2 (node74) : | ||
| + | $ ldapsearch -x -LLL -H ldap://egee-bdii.cnaf.infn.it:2170 -b Mds-Vo-name=GRIF-IRFU,Mds-Vo-name=GRIF,mds-vo-name=local,o=grid 'objectclass=GlueSubCluster' | grep node74 | ||
| + | $ | ||
| + | |||
| + | Ne rendait rien…. | ||
| + | Ajout de ces 2 variables dans le profile de M2 ( CREAM CE) : | ||
| + | |||
| + | variable CE_HOST ?= 'node74.datagrid.cea.fr'; | ||
| + | variable GIP_CLUSTER_PUBLISHER_HOST ?= CE_HOST; | ||
| + | |||
| + | == 5) Résoudre les problèmes de publication (4444 jobs waiting…) == | ||
| + | === 1)Inclure le client NFS sur M1 === | ||
| + | variable NFS_CLIENT_ENABLED ?= true; | ||
| + | |||
| + | Car 'M1 renseigne le GIP de M2 dans le software area de dteam via un cron sur M1'. | ||
| + | Attention malgré l’option '''no_root_squash''' dans l’export du serveur NFS, il faut que les 2 fichiers : | ||
| + | gip-ce-dynamic-info-maui.cache | ||
| + | gip-ce-dynamic-info-scheduler.cache | ||
| + | |||
| + | Existent dans ce software area et appartiennent à root. | ||
| + | Faire un chmod 777 sur le serveur NFS le temps du cron sur M1, puis refaire un chown 755 (à analyser ?) | ||
| + | |||
| + | === 2)un des plugin ('/opt/lcg/libexec/lcg-info-dynamic-maui') est buggé === | ||
| + | export PYTHONPATH=/opt/lcg/lib/python:${PYTHONPATH} ; python /opt/lcg/libexec/lcg-info-dynamic-maui --host node07.datagrid.cea.fr --max-normal-slots 2236 --ce-ldif /var/glite/static-file-all-CE-pbs.ldif --diagnose-output /tmp/maui-reservations.list | ||
| + | Traceback (most recent call last): | ||
| + | File "/opt/lcg/libexec/lcg-info-dynamic-maui", line 244, in ? | ||
| + | if not queueParams: | ||
| + | File "/usr/lib64/python2.4/site-packages/pbs/PBSQuery.py", line 351, in __getattr__ | ||
| + | raise PBSError(error) | ||
| + | PBSQuery.PBSError: Attribute key error: __nonzero__ | ||
| + | |||
| + | |||
| + | '''Recuperer celui de grid33.lal.in2p3.fr''' | ||
| + | Patch à venir.... | ||
= FTS = | = FTS = | ||
Latest revision as of 16:26, 29 août 2011
Sommaire
- 1 Mise hors service du LCG-CE (réinstallé en serveur (Maui + torque Only))
- 1.1 1)M1 : serveur Maui + torque Only en SL5
- 1.2 2) Déplacer le site BDII sur une autre machine (anciennement sur M1 (le LCG-CE))
- 1.3 3) Résoudre l’erreur : Bad UID for job execution
- 1.4 4) Resoudre le probleme de ‘resource not available’ vu par les WMS :
- 1.5 5) Résoudre les problèmes de publication (4444 jobs waiting…)
- 2 FTS
- 3 Installation et Configuration d'une VO-BOX ALICE
- 3.1 Introduction
- 3.2 Ressources disques requises
- 3.3 Les ports à ouvrir pour la VO-BOX au niveau du router
- 3.4 Le profile de la VO-BOX sous Quattor
- 3.5 Après l'installation via Quattor de la machine
- 3.6 Durée du proxy
- 3.7 Backup
- 3.8 Se connecter à la VO-BOX depuis le UI
- 3.9 Utiliser le serveur myproxy
- 3.10 Start/Stop des services
- 3.11 Expiration du proxy
- 3.12 Monitoring / Accounting
- 3.13 Liens Utiles
- 4 LEMON : Sytème de Monitoring Client/Serveur
- 5 Test sur le réseaux datagrid.cea.fr: Iperf
- 6 Test sur le réseaux datagrid.cea.fr: Transfert de fichiers -1ere PHASE-
- 7 Test sur le réseaux datagrid.cea.fr: Transfert de fichiers -2eme PHASE (3 SE-DISK au DAPNIA et multi threading)-
- 8 Priorites locales Filtre TORQUE-
- 9 Configuration thumper
- 9.1 Formatage des disks:
- 9.2 Creation des Raids logiciel:
- 9.3 Pour les drivers:
- 9.4 Test Performance Lecture/ecriture
- 9.5 Configuration Reseaux avec 2 intefaces bond
- 9.6 Configuration Reseaux avec 1 intefaces bond
- 9.7 Probleme sur les cartes reseaux supplémentaires:
- 9.8 driver carte réseaux
- 9.9 Test iperf
- 9.10 Test Performance DISK+NETWORK avec DPM
- 9.11 DPM et XROOTD
- 9.12 Conclusion
Mise hors service du LCG-CE (réinstallé en serveur (Maui + torque Only))
Mise hors service du LCG-CE via Quattor sur un cluster avec :
-une machine, M1 :(lcg-CE +Maui + torque) et
- une deuxième Machine, M2 : CREAM-CE
La Première machine étant réinstallé en serveur (Maui + torque Only)
1)M1 : serveur Maui + torque Only en SL5
a)Inclure un nouveau type de machine dans M1
include { 'machine-types/torque_server' (a la place du glite_ce)
b)Ajouter la derniere version de maui
'/software/packages'=pkg_repl('maui','3.3.1-1.sl5','x86_64');
'/software/packages'=pkg_repl('maui-client','3.3.1-1.sl5','x86_64');
'/software/packages'=pkg_repl('maui-server','3.3.1-1.sl5','x86_64');
c) SL5
Deplacer le profile ainsi que le template 'pro_lcg2_config_site_maui.tpl' dans le cluster glite 3.2 et modifier le '*nodes_properties.tpl' (install SL5)
d) Declarer une nouvelle variable
variable LRMS_SERVER_HOST dans 'pro_lcg2_config_site.tpl' et 'pro_site_common_config.tpl'
Template modifié lors de ces étapes:
Suppression cfg/clusters/irfu/glite-3.1/profiles/profile_node07.tpl Suppression cfg/clusters/irfu/glite-3.1/site/pro_lcg2_config_site_maui.tpl Ajout cfg/clusters/irfu/glite-3.2/profiles/profile_node07.tpl Ajout cfg/clusters/irfu/glite-3.2/site/pro_lcg2_config_site_maui.tpl Envoi cfg/sites/dapnia/site/config/dapnia_nodes_properties.tpl M cfg/clusters/irfu/test-glite-3.2/site/pro_lcg2_config_site.tpl M cfg/clusters/irfu/glite-3.1_MPI/profiles/profile_node16.tpl M cfg/clusters/irfu/glite-3.1_MPI/site/pro_lcg2_config_site.tpl M cfg/clusters/irfu/glite-3.2_MPI/site/pro_lcg2_config_site.tpl M cfg/sites/dapnia/site/pro_site_common_config.tpl M cfg/sites/dapnia/site/pro_site_ui_dapnia_users_env.tpl M cfg/sites/dapnia/site/pro_lcg2_config_site.tpl
2) Déplacer le site BDII sur une autre machine (anciennement sur M1 (le LCG-CE))
Enlever les variable de configuration de BDII sur M1 et les ajouter sur une autre machine (LFC exemple) :
variable BDII_TYPE='site'; # site bdii variable BDII_SUBSITE_ONLY = false; variable BDII_SUBSITE = 'IRFU';
3) Résoudre l’erreur : Bad UID for job execution
http://grid.pd.infn.it/cream/field.php?n=Main.ErrorMessagesReportedByCREAMToClient#badui en rajoutant le fichier mentionné: /etc/hosts.equiv
4) Resoudre le probleme de ‘resource not available’ vu par les WMS :
En fait le système d’information ne marchait pas bien sur M2 (node74) :
$ ldapsearch -x -LLL -H ldap://egee-bdii.cnaf.infn.it:2170 -b Mds-Vo-name=GRIF-IRFU,Mds-Vo-name=GRIF,mds-vo-name=local,o=grid 'objectclass=GlueSubCluster' | grep node74 $
Ne rendait rien…. Ajout de ces 2 variables dans le profile de M2 ( CREAM CE) :
variable CE_HOST ?= 'node74.datagrid.cea.fr'; variable GIP_CLUSTER_PUBLISHER_HOST ?= CE_HOST;
5) Résoudre les problèmes de publication (4444 jobs waiting…)
1)Inclure le client NFS sur M1
variable NFS_CLIENT_ENABLED ?= true;
Car 'M1 renseigne le GIP de M2 dans le software area de dteam via un cron sur M1'. Attention malgré l’option no_root_squash dans l’export du serveur NFS, il faut que les 2 fichiers :
gip-ce-dynamic-info-maui.cache gip-ce-dynamic-info-scheduler.cache
Existent dans ce software area et appartiennent à root. Faire un chmod 777 sur le serveur NFS le temps du cron sur M1, puis refaire un chown 755 (à analyser ?)
2)un des plugin ('/opt/lcg/libexec/lcg-info-dynamic-maui') est buggé
export PYTHONPATH=/opt/lcg/lib/python:${PYTHONPATH} ; python /opt/lcg/libexec/lcg-info-dynamic-maui --host node07.datagrid.cea.fr --max-normal-slots 2236 --ce-ldif /var/glite/static-file-all-CE-pbs.ldif --diagnose-output /tmp/maui-reservations.list
Traceback (most recent call last):
File "/opt/lcg/libexec/lcg-info-dynamic-maui", line 244, in ?
if not queueParams:
File "/usr/lib64/python2.4/site-packages/pbs/PBSQuery.py", line 351, in __getattr__
raise PBSError(error)
PBSQuery.PBSError: Attribute key error: __nonzero__
Recuperer celui de grid33.lal.in2p3.fr Patch à venir....
FTS
'connaitre la list des channels:'
glite-transfer-channel-list -s cclcgftsprod.in2p3.fr IN2P3-IRFU
'reactiver un channel'
glite-transfer-channel-setvoshare -s cclcgftsprod.in2p3.fr <CHANNEL_NAME> atlas 100
Installation et Configuration d'une VO-BOX ALICE
Introduction
Un site grille qui souhaite supporter l'expérience ALICE, doit installer une VO-BOX. ALICE utilise AliEN (Alice ENvironment) comme plateforme logicielle pour la simulation et l'analyse des données. Alien est installé sur chaque VO-BOX. C'est le CE d'Alien qui soumet les Job Agents (JAs) au CE du site. Les JAs vont ensuite chercher les jobs dans central Task Queue de Alien. Les jobs écrivent via xrootd (directement vers le CERN pour le moment). Comme il n'y a pas encore d'interface xrootd/SRM, chaque VO-BOX doit fournir un stockage xrootd qui peut être sur un disque local.
Les documents à lire impérativement (en plus de ce guide) sont:
* ALICE LCG VO-Box Installation Guide * VOBOX Security and Operations Questionnaires
La VO-BOX n'est pas consommatrice en CPU et RAM. N'importe quel PC récent(Pentium+) avec 2GB+ de RAM peut faire l'affaire. Cependant un bon hardware est recommandé pour minimiser la fréquence des pannes.
Ressources disques requises
* Partition / (root) : au moins 2 GB * Partition /var : y prévoir 10-15 GB d'espace pour les logs d'Alien * /data (ou un autre nom) : partition local pour xrootd (prévoir 3G par job slot)
Remarques:
1. xrootd: sur un site avec plus de 30 job slots, passer si possible au mode "head node + xrootd servers" pour des raisons de performances 2. "/home" doit être local pour des raisons de performances et de gestion des "locks"
Les ports à ouvrir pour la VO-BOX au niveau du router
* 1975/tcp (gsissh): inbound from 137.138.0.0/16 and 192.16.186.192/26 * 1094/tcp(xrootd) * 8082/tcp (Storage Adapter) * 8083 (FTD) * 8084/tcp (Site Proxy) * 9991/tcp (PackMan) : Inbound from 137.138.0.0/16 * 1093/tcp (proofd)
Le profile de la VO-BOX sous Quattor
Dans clusters/<nom_site>-glite-x.y.z/profiles/profile_<nom_vobox>.tpl, faire:
{{{
include pro_<nom_site>_alice_glite_vobox; (voir cfg/clusters/ipno-glite-3.0.0/profiles/profile_ipnvobox.tpl)
}}}
Dans sites/<nom_site>/machine-types, créer pro_<nom_site>_alice_glite_vobox.tpl et pro_<nom_site>_alice_vobox_config.tpl
Vous pouvez copier et adpater les templates de l'IPNO ou du DAPNIA.
Après l'installation via Quattor de la machine
* Demander et installer le certificat serveur GRID-FR de la mchine
* Vérifier que les utilisateurs alis et alip existent dans /etc/passwd
* Verifier que Patricia Lorenzo Mendez et Artem Trunov sont bien mappés sur
alis dans /etc/grid-security/grid-mapfile et qu'il y a quelqu'un mappé
sur alip. Question ouverte: faut-il creer les pool accounts ? Ou faut-il
créer uniqument les comptes alis, alip nécessaires pour ALICE ?
* Dans /etc/shadow vous devez avoir '*' dans le champ 'password', sinon le logingsissh ne marchera pas. Donc il faut remplacer '!!' ou '!*NP*' par '*'
{{{
[root@ipnvobox etc]# grep alis /etc/shadow alis:*:13574:0:99999:7:::
}}}
* Vérifier que le serveur GSISSH tourne sur la VOBOX sur le port 1975.
* Vérifier que $MYPROXY_SERVER pointe bien sur myproxy.cern.ch
* Vérifier que la expérimental software area ($VO_ALICE_SW_DIR) est bien accessible via NFS depuis la VO-BOX et writeable par alis. Il faut au moins 5GB d'espace libre pour le soft d'ALICE.
* Vérifier que la partition /data pour xrootd existe et appartient à alis (/data doit être crée sous Quattor ou à la main)
{{{
[root@ipnvobox root]# ls -ld /data drwxr-xr-x 19 alis alice 4096 Dec 14 13:22 /data
}}}
* Créer un directory pour les logs d'Alien (ex: /var/log/alis). Il doit appartenir à alis et nécessite 10-15 GB libre.
{{{
[root@ipnvobox root]# ls -ld /var/log/alis drwxrwxrwx 10 alis alice 4096 Mar 2 16:54 /var/log/alis
}}}
* Configurer le proxy-renewal service. MAIS, le script /opt/vobox/templates/voname-box-proxyrenewal n'est pas encore exécuté automatiquement. Cal a prévu de corriger le probleme. Donc si après l'installation de la VO-BOX, il manque alice-box-proxyrenewal dans /etc/cron.d/ et dans /etc/init.d/ ainsi que start, stop, agents et info-provider dans /opt/vobox/alice/, alors faire:
1. créer /etc/cron.d/alice-box-proxyrenewal:
{{{
[root@ipnvobox root]# cat /etc/cron.d/alice-box-proxyrenewal
- !/bin/sh
20 2,8,14,20 * * * root (PATH=/sbin:/bin:/usr/sbin:/usr/bin; /sbin/service alice-box-proxyrenewal proxy)
}}}
2. copier /opt/vobox/templates/voname-box-proxyrenewal dans
/tmp/alice-proxy-renewal.sh, adpatez-le et exécutez-le (le script que j'ai
utilisé est en attachement: alice-proxy-renewal.sh).
3. vous devez alors retrouver les directories qui manquaient:
{{{
[root@ipnvobox alice]# ls -l total 44 drwx------ 2 alis alice 4096 Jul 19 2006 agents -rw-rw-rw- 1 alis alice 0 Nov 14 09:09 edglog.log drwx------ 2 alis alice 4096 Jul 19 2006 info-provider drwx------ 2 alis alice 4096 Mar 1 04:02 log drwx------ 2 alis alice 4096 Mar 2 17:19 proxy_repository -rw------- 1 alis alice 13750 Mar 2 17:04 _registerer_proxies.db -r-------- 1 alis alice 2690 Mar 2 14:20 renewal-proxy.pem drwx------ 2 alis alice 4096 Aug 6 2006 start drwx------ 2 alis alice 4096 Aug 5 2006 stop
}}} * Envoyer un e-mail à: Patricia.Mendez@cern.ch, latchezar.betev@cern.ch et trunov@cc.in2p3.fr :
1. demander que la machine soit enregistrée 'as trusted host' dans myproxy.cern.ch dans LDAP (il faut fournir le DN de la VOBOX). 2. fournir les informations suivantes dans le mail:
* hostname de la VO-BOX * le nom des users: alicesgm (alis dans GRIF), alip (ALICE Production) * le nom directory pour xrootd (ex: /data) * le nom du SE/DPM Server (ex: ipnsedpm.in2p3.fr) * le nom du serveur LFC (ex: grid14.lal.in2p3.fr) et le catalogue pour ALICE (/grid/alice) * le nom du RB (ex: grid09.lal.in2p3.fr) * le nom du CE et de la queue batch (ex: ipnls2001.in2p3.fr:2119/jobmanager-pbs-alice) * le path pour le experiment software area (ex:VO_ALICE_SW_DIR=/ipn/storage1/exp_soft/alis, zone "NFS shared" avec les WNs) * Installer Alien ou demander que Artem ou Patricia vous l'installe. * S'inscrire individullement dans le projet ALICE (voir avec un physicien d'ALICE du Labo et avec le Secrétariat d'ALICE) : 1. demander un logon au CERN (si vous n'en avez pas déjà) 2. demander à être enregistré comme membre du projet ALICE * Inscrivez-vous dans AliEn en suivant les étapes sur la page http://alien.cern.ch/twiki/bin/view/Alice/UserRegistration 1. Vous serez amenés à vous inscrire dans la VO ALICE (si ce n'est pas déjà fait) sur https://lcg-voms.cern.ch:8443/vo/alice/vomrs 2. Ensuite vous pourrez vous inscrire dans AliEn ("5. Register with AliEn" sur https://alien.cern.ch:8443/twiki/bin/UserReg * Demander ensuite à être mapé sur 'alidprod' si vous voulez pouvoir utiliser AliEn sous votre nom (ALIEN_USER=user_name dans ~alis/.alien/Environment) la VO-BOX (start/stop des services par exemples) * Mettre dans /etc/motd des informations utiles à afficher lors de la connexion [gsi]ssh: LFC server, catalog pour alice, zone pour xrootd, etc.
Durée du proxy
Vérifier dans /opt/lcg/sbin/vobox-renewd qu'on a '-t 48' :
{{{
${GLOBUS_LOCATION}/bin/myproxy-get-delegation -a ${VOBOX_PROXY_REPOSITORY}/${CERT} -d -o $TMP_PROXY -t 48 2>&1 > /dev/null
}}}
Il s'agit d'un problème qui devrait être résolu dans le futur
Backup
Faire régulièrement des sauvegardes de ~alis, /opt/vobox et des logs d'Alien (ex: /var/log/alis)
Se connecter à la VO-BOX depuis le UI
Faire 'gsissh -l user -p port_GSISSH <vobox_name> '
{{{
[diarra@ipngrid01 ~]$ gsissh -l alis -p 1975 ipnvobox
}}}
Utiliser le serveur myproxy
Sur le UI:
{{{
myproxy-init -s myproxy.cern.ch -d -n -t 48 -c 720 gsissh -l alis -p 1975 <vobox_name>
}}}
Sur la VO-BOX:
{{{
vobox-proxy --vo alice --proxy-safe 3600 --myproxy-safe 259200 --email <votre_e-mail> register
}}}
Pour s'assurer que le proxy est renouveler automatiquement, vérifier que vous avez dans /opt/vobox/alice/log/events.log une ligne du genre:
{{{
9/07/06 14:35:56 : Proxy for DN "/O=GRID-FR/C=FR/O=CNRS/OU=IPNO/CN=Christophe Diarra/CN=proxy/CN=proxy/CN=proxy" successfully renewed
}}}
Dans /opt/vobox/alice/proxy_repository/ vous trouverez le proxy.
Start/Stop des services
Les services peuvent être démarrés un par un. Les services disponibles sont : Monitor, SE, CE, PackMan, Monalisa.
Un script permet de les démarrer ou de les arrêter dans le bon ordre:
stop
Pour démarrer ou arreter un seul service :
StopServiceName
Exemple: $VO_ALICE_SW_DIR/alien/scripts/lcg/lcgAlien.sh StopCE $VO_ALICE_SW_DIR/alien/scripts/lcg/lcgAlien.sh StartCE
Expiration du proxy
Quand vous recevez un mail indiquant que le proxy est sur le point d'expirer (3 jours avant ?), ou si les logs le signalent, il faut renouveler le proxy sur le serveur myproxy depuis le UI.
{{{
[root@ipnvobox log]# more /opt/vobox/alice/log/events.log ... 11/26/06 15:03:05 : Myproxy lifetime (256228 sec) shorter than security threshol d (259200 sec) 11/26/06 15:03:05 : ... for DN /O=GRID-FR/C=FR/O=CNRS/OU=IPNO/CN=Christophe Diar ra 11/26/06 15:03:05 : sendind notification email to diarra@ipno.in2p3.fr. SUCCESSF ULL
}}}
Sur le UI:
{{{
[diarra@ipnls2011 my]$ myproxy-info -d -s myproxy.cern.ch username: /O=GRID-FR/C=FR/O=CNRS/OU=IPNO/CN=Christophe Diarra owner: /O=GRID-FR/C=FR/O=CNRS/OU=IPNO/CN=Christophe Diarra
timeleft: 52:25:26 (2.2 days)
[diarra@ipnls2011 my]$ myproxy-init -s myproxy.cern.ch -d -n -t 48 -c 720 Your identity: /O=GRID-FR/C=FR/O=CNRS/OU=IPNO/CN=Christophe Diarra Enter GRID pass phrase for this identity: Creating proxy ............................................ Done Proxy Verify OK Your proxy is valid until: Wed Dec 27 09:56:25 2006 A proxy valid for 720 hours (30.0 days) for user /O=GRID-FR/C=FR/O=CNRS/OU=IPNO/CN=Christophe Diarra now exists on myproxy.cern.ch.
}}}
Monitoring / Accounting
* ALICE Monitoring with MonALISA * ALICE Dashboard : Job Summary
Liens Utiles
Debugging & Troubleshooting the ALICE LCG Vo-Box
VO-box HowTo - description, installation, testing
VOBOX Security and Operations Questionnaires
LCG VOBox Operations Recommendations and Questionnaire
How to install xrootd on data servers
LEMON : Sytème de Monitoring Client/Serveur
http://lemon.web.cern.ch/lemon/ http://lemon.web.cern.ch/lemon/doc/installation/installation.html
Installation du Serveur Lemon via quattor en SL4
Utilser les 2 templates : {{{ pro_software_lemon_server_sl4_i386; pro_service_lemon_server; }}}
Qui vont:
1) installer les RPMs necessaires
{{{ ("edg-fabricMonitoring-server","2.13.0-3","i386"); ("rrdtool","1.0.49-2.1.el3.rf","i386"); ("lrf","1.0.7-15","i386"); ("ncm-fmonagent","1.0.32-1","noarch"); ("perl-TimeDate","2.22-1","noarch"); ("httpd","2.0.52-22.ent","i386"); ("httpd-suexec","2.0.52-22.ent","i386"); ("system-config-httpd","1.3.1-1","noarch"); ("php-ldap","4.3.9-3.15","i386"); ("php-gd","4.3.9-3.15","i386"); ("php-imap","4.3.9-3.15","i386"); ("php-pear","4.3.9-3.15","i386"); ("php","4.3.9-3.15","i386"); ("oracle-xe-univ","10.2.0.1-1.0","i386"); ("cx_Oracle","4.1-1","i386"); ("lemon-ora-admin","1.0.4-96","noarch");
- lemon-OraMon probleme de dependance: l'installer avec --nodeps (info from Miroslav Sicket CERN)
("lemon-OraMon","1.2.0-1","i386");}}} }}}
2) configurer les fichiers suivant :
{{{
/etc/lemon/server/lemon-oramon-server.conf
/var/www/html/lrf/config.php
/var/spool/edg-fmon-server/nodes.map
/etc/lemon/lemonmrd.conf
}}}
3) et demarrer les 2 demons :
{{{ /etc/init.d/OraMon /etc/init.d/lemonmrd }}}
Configuration Hors Quattor
1) Configuration de la Base de Donée:
{{{
/etc/init.d/oracle-xe configure
. /usr/lib/oracle/xe/app/oracle/product/10.2.0/server/bin/oracle_env.sh
sqlplus system
SQL> EXEC DBMS_XDB.SETLISTENERLOCALACCESS(FALSE);
/etc/init.d/oracle-xe start }}}
2) Ajouter l'utilisateur lemon
via l'interface http://ma_machine:port_choisi/apex
3) Configuration de Oramon :
{{{ lemon-ora.admin --create-schema -d xe --data-tablespace=USERS --index-tablespace=USERS lemon-ora.admin --file=/etc/oramon-server.conf -d xe --all --data-tablespace=USERS --index-tablespace=USERS lemon-ora.admin --file=/etc/oramon-server.conf -d xe -u lemon --create-las --data-tablespace=USERS --index-tablespace=USERS }}}
4) exporter les variables Oracle :
{{{
export LD_LIBRARY_PATH=/usr/lib/oracle/xe/app/oracle/product/10.2.0/server/lib:/usr/lib/oracle/10.2.0.3/client/lib
export ORACLE_SID=XE
export PATH=$PATH:/usr/lib/oracle/xe/app/oracle/product/10.2.0/server/bin
export ORACLE_HOME=/usr/lib/oracle/xe/app/oracle/product/10.2.0/server
export TNS_ADMIN=/usr/lib/oracle/xe/app/oracle/product/10.2.0/server/network/admin
export PYTHONPATH=/usr/lib/python2.2/site-packages
export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
}}}
Dans tous les fichiers de demarrage suivant :
{{{
/etc/init.d/lemonmrd
/etc/init.d/httpd
/etc/sysconfig/OraMon
}}}
5) Et verifier ensuite les logs, et que le serveur collecte bien des données :
{{{ /var/log/lemonmrd.log /var/www/html/lrf/data }}}
Ajout de nouvelles sondes/metriques
I) Sur le client
a)
[root@node07 sensor-example]# cat /etc/lemon/agent/sensors/torque_maui.conf
torque_maui
CommandLine /usr/bin/perl /usr/libexec/sensors/lemon-sensor.pl RunningJobs
MetricClasses
torque_maui.RunningJobs
b)
[root@node07 sensor-example]# cat /etc/lemon/agent/metrics/torque_maui.conf
20047
MetricName Jobsrunning
MetricClass torque_maui.RunningJobs
Timing 3600 0
c)
[root@node07 sensor-example]# cat /usr/libexec/sensors/RunningJobs.pm
#!/usr/bin/perl -w
package torque_maui;
# modules
use diagnostics;
use strict;
# the sensor API interface
use sensorAPI;
# register module name and version
registerVersion("lemon-sensor-torque_maui", "1.0.0-1");
# register the sensors metric classes
registerMetric("torque_maui.RunningJobs", "report the Running Jobs", "torque_maui::RunningJobs");
sub RunningJobs_sample() {
# All function hooks in the sensor API: _sample(), _initialise(), _periodicCheck(), _destroy()
# are passed a hash as the first argument. This hash provides the function with the ability to
# access the methods and variables of the metric instance/object. This is Perls implementation
# of Object Orientation
my $obj = shift;
# variables
my $line = `/usr/bin/showq -r | echo \$((\$(wc -l)-4))`;
$obj->storeSample01($line);
# All functions called by the sensor API must return a value
# - if the sampling was successful you the return code should be 0 and -1 on error
return 0;
}
1;
#-- End-of-File --------------------------------------------------------------------------------------#
II) Pour le serveur
1) Pour Oramon
a) modifier le fichier /etc/oramon-server.conf
………..
torque_maui.RunningJobs
Description Running jobs on the CE?
Fields
Running_Jobs
Type INTEGER
MetricUnit count
MetricScale 1
……………..
20047
MetricClass torque_maui.RunningJobs
MetricName Jobsrunning
Description Running Jobs on the CE?
TableName _20047
Metric classes part into corresponding metric class part, metric instance into metric instances (be carefull about the tabs).
b) sourcer laes variables d'environnement oracle :
. /usr/lib/oracle/xe/app/oracle/product/10.2.0/server/bin/oracle_env.sh
c) mettre a jour la Database:
lemon-ora.admin --file=/etc/oramon-server.conf -d xe -u lemon --all --data-tablespace=USERS --index-tablespace=USERS
2) Pour LRF
a) # tail -3 /var/spool/edg-fmon-server/metrics.map
182 20015 /home.use 183 30050 exitCodeNFS 184 20047 RunningJobs
b)# more /etc/lemon/lemonmrd.conf
……………..
RunningJobs=Jobsrunning:Running_Jobs
……………..
[node07.datagrid.cea.fr] type=host metrics=+RunningJobs
c) #grep -i job /var/www/html/lrf/metric_map.php
"RunningJobs" => array("RunningJobs","Jobs running","count",1,0,'Jobsrunning.Running_Jobs'),
1 => array('name' => 'JOBS STATISTICS', 'y-axis' => 'count', 'stack' => false, 'base' => 1,
'metrics' => array( 0 => array('name' => 'RunningJobs', 'summary' => true, 'title' => 'Running Jobs')
Pour configurer les alarmes
a) créer un fichier xml par machine:
{{{
- cat /tmp/my_cnf_node07.xml
<?xml version = '1.0'?> <CDBSEARCHLIST> <HOST ID="node07.datagrid.cea.fr" CLUSTER ="GRID_SERVICES" SUBCLUSTER ="" IMPORTANCE ="0" SURESTATUS ="TRUE" NOCONTACTTIMEOUT ="660" PINGTIMEOUT ="" /> </CDBSEARCHLIST>
}}}
b) mettre a jour la Database:
{{{
- lemon-ora.entities -u lemon -d xe -c /tmp/my_cnf_node07.xml
}}}
Problemes rencontrés
ne pas oublier d'exporter les variables oracles
le fichies nodes.map ne doit pas avoir de lignes vides
Les Symlink avec cette version d'apache ne fonctionne pas (on utlisie /var/www/html/lrf/data au lieu de /var/spool/data)
Php avec oci8 tres sensibles aux versions (plus de soucis avec les versions SL4 ci dessus)
Test sur le réseaux datagrid.cea.fr: Iperf
Le 20/03/2007
Avec 5 threads :
Lyon -> Saclay : 550Mb/s (peu variable) ;
Saclay -> Lyon : 600 Mb/s (très variables de 250 Mb/s à 750 Mb/s)).
Avec 1 thread : 300 Mb/s dans les 2 sens
Test sur le réseaux datagrid.cea.fr: Transfert de fichiers -1ere PHASE-
Sites impliqués
- T1 CC-IN2P3
- Contacts : David Bouvet, Lionel Schwarz
- SE : ccsrm.in2p3.fr
- Endpoint transferts DAPNIA-CC : /pnfs/in2p3.fr/data/dteam/disk/dapnia/
- T2 GRIF
- Contacts : Christine Leroy
- SE-DAPNIA : node12.datagrid.cea.fr
- GlueServiceEndpoint: httpg://node12.datagrid.cea.fr:8443/srm/managerv1
- GlueSAPath: /dpm/datagrid.cea.fr/home/dteam
- SE-LAL : grid05.lal.in2p3.fr
conditions de transferts pour FTS
Les transferts sont initiés depuis node02.datagrid.cea.fr
- Avant tout transfert, il faut un proxy valide déposé sur un serveur MyProxy pour permettre au serveur FTS de renouveler un proxy expiré en cours de transfert
myproxy-init -s cclcgproxli01.in2p3.fr -d
glite-transfer-channel-list -s https://cclcgftsprod01.in2p3.fr:8443/glite-data-transfer-fts/services/ChannelManagement GRIF-IN2P3
glite-transfer-channel-set -s https://cclcgftsprod01.in2p3.fr:8443/glite-data-transfer-fts/services/ChannelManagement -f 10 -T 1 GRIF-IN2P3
Les tests de transferts
-Script de test des transferts FTS proposé par GridPP à l'adresse : http://www.gridpp.ac.uk/wiki/Transfer_Test_Python_Script_HOWTO
-Le wiki GriPP est une mine d'informations : http://www.gridpp.ac.uk/wiki/Main_Page
CC->DAPNIA
set SourceURL="srm://ccsrm.in2p3.fr:8443/" set DestURL="srm://node12.datagrid.cea.fr:8443/dpm/datagrid.cea.fr/home/dteam/"
liste des fichiers:
srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00007 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00008 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00009 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00011 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00012 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00013 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00014 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00015 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00016 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00017 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00018 srm/managerv1?SFN=/pnfs/in2p3.fr/data/dteam/dapnia/cleroy/ATLAS-file00019
DAPNIA -> CC
set SourceURL="srm://node12.datagrid.cea.fr:8443/dpm/datagrid.cea.fr/home/dteam/dapnia/" set DestURL="srm://ccsrm.in2p3.fr:8443/pnfs/in2p3.fr/data/dteam/disk/dapnia/"
liste des fichiers (1 seul SE-DISK)
cleroy/ATLAS-file00007 cleroy/ATLAS-file00008 cleroy/ATLAS-file00009 cleroy/ATLAS-file00011 cleroy/ATLAS-file00012 cleroy/ATLAS-file00013 cleroy/ATLAS-file00014 cleroy/ATLAS-file00015 cleroy/ATLAS-file00016 cleroy/ATLAS-file00017 cleroy/ATLAS-file00018 cleroy/ATLAS-file00019
en parrallele avec n=10 pour les 2 type de transfet, pour durer environ 20 minutes (1Gb/s).
FTS configuré avec (f6;T2).
ESSAI du nbre de | (fichier;stream) | Bande passante(Mb/s) | ------------------+-----------------------+ | (f8;T1) | 242 | | (f6;T1) | 301 | | (f3;T1) | 302 | | (f2;T1) | 185 | | (f6;T2) | 312 | | (f6;T6) | 284 | | (f6;T4) | 280 |
Resultat 26/04/2007 :
D-CC
Transfer Bandwidth Report: 110/120 transferred in 2668.16920614 seconds 81081938300.0 bytes transferred. Bandwidth: 243.108834667Mb/s
CC-D
Transfer Bandwidth Report: 120/120 transferred in 3033.88385892 seconds 88453023600.0 bytes transferred. Bandwidth: 233.240368355Mb/s
Débit réseaux pour le SE DISK du DAPNIA (derriere node12):
http://lcg2.in2p3.fr/wiki/images/Node11_net_fts_26042007.gif
{kind=link}
Débit réseaux routeur datagrid.cea.fr:
http://lcg2.in2p3.fr/wiki/images/Routeur_datagridceafr_26042007.png
{kind=link}
utilisation de:
- filetransfer.py entre DAPNIA <-> Lyon (SE <-> SE)
- globus_url_copy et lcg-cr entre DAPNIA <-> Orsay (UI <-> SE)
Le 02/05/2007: Meme occupation réseaux :300Mb/s
CONCLUSION PRELIMINIARE
=> Ces tests avaient pour but d'occuper le plus possible la bande passante de notre réseaux datagrid.cea.fr, pour s'assurer que le routeur tenait bien la charge
=> Nous n'avons pas reussi à occuper toute la bande passante: tests à poursuivre avec plus de client/serveur => Le comble de l'informaticien: réussir à faire mieux que ses utilisateurs:
One day, One atlas physicit, Many jobs:
http://lcg2.in2p3.fr/wiki/images/Node11.datagrid.cea.fr.rrd_NUMKBREADAVG_d.gif
{kind=link}
Débit réseaux SE DISK, le 16/06/2006
Test sur le réseaux datagrid.cea.fr: Transfert de fichiers -2eme PHASE (3 SE-DISK au DAPNIA et multi threading)-
Transfert FTS: (CC->DAPNIA) // (DAPNIA->CC) avec plusieurs SE-DISK du DAPNIA (node11, node18, node20)
Transfert: FTS (CC->DAPNIA) // FTS (DAPNIA->CC) ) // globus-url-copy (UI DAPNIA -> SE LAL) // globus-url-copy (SE LAL -> UI DAPNIA)
Priorites locales Filtre TORQUE-
http://lcg2.in2p3.fr/wiki/images/Submit_filter.txt
Configuration thumper
La DOc: http://www.sun.com/products-n-solutions/hardware/docs/pdf/820-1151-10.pdf
http://doc.fedora-fr.org/RAID_Logiciel:_Comment_Installer_et_G%C3%A9rer_un_System_Raid
Formatage des disks:
Il faut des partitions du type type Linux raid autodetect (type fd)
for i in /dev/sda /dev/sdaa /dev/sdab /dev/sdad /dev/sdae /dev/sdaf /dev/sdag /dev/sdah /dev/sdai /dev/sdaj /dev/sd /dev/sdal /dev/sdam /dev/sdan /dev/sdao /dev/sdap /dev/sdaq /dev/sdar /dev/sdas /dev/sdat /dev/sdau /dev/sdav /dev/sdd /dev/sde /dev/sdf /dev/sdg /dev/sdh /dev/sdi /dev/sdj /dev/sdk /dev/sdl /dev/sdm /dev/sdn /dev/sdo /dev/sdp /dev/sdq /dev/sdr /dev/sds /dev/sdt /dev/sdu /dev/sdv /dev/sdw /dev/sdx /dev/sdz; do export $i; /root/script_raid $i; done
[root@node23 ~]# more /root/script_raid sfdisk -f $1 << EOF 0 60801 fd ; ; ; EOF
Pour verifier:
# for i in /dev/sda /dev/sdaa /dev/sdab /dev/sdad /dev/sdae /dev/sdaf /dev/sdag /dev/sdah /dev/sdai /dev/sdaj /dev/sdak /dev/sdal /dev/sdam /dev/sdan /dev/sdao /dev/sdap /dev/sdaq /dev/sdar /dev/sdas /dev/sdat /dev/sdau /dev/sdav /dev/sdd /dev/sde /dev/sdf /dev/sdg /dev/sdh /dev/sdi /dev/sdj /dev/sdk /dev/sdl /dev/sdm /dev/sdn /dev/sdo /dev/sdp /dev/sdq /dev/sdr /dev/sds /dev/sdt /dev/sdu /dev/sdv /dev/sdw /dev/sdx /dev/sdz; do sfdisk --list $i ; done | more
Creation des Raids logiciel:
Conseil de SUN:
"Diff Raid 5 config does not change the availability that much, Raid 5 is one way parity, if you lose two disks in the same raid group, you lose the data. The difference is probability of losing two disks is higher when you have higher number of disks in a raid group. We usually suggest using one disk out of each controller for parity, (six controller total), 5+1 configuration, 8 raid groups. Overhead is 1/6 about 16% capacity loss. add the OS disk, 20TB."
mdadm --create /dev/md1 --level=5 --raid- devices=6 /dev/sdab1 /dev/sdt1 /dev/sdar1 /dev/sdaj1 /dev/sdl1 /dev/sdd1 mdadm --create /dev/md2 --level=5 --raid- devices=6 /dev/sdaf1 /dev/sdx1 /dev/sdav1 /dev/sdan1 /dev/sdp1 /dev/sdh mdadm --create /dev/md3 --level=5 --raid- devices=6 /dev/sdaa1 /dev/sds1 /dev/sdaq1 /dev/sdai1 /dev/sdk1 /dev/sdc1 mdadm --create /dev/md4 --level=5 --raid- devices=6 /dev/sdae1 /dev/sdw1 /dev/sdau1 /dev/sdam1 /dev/sdo1 /dev/sdg1 mdadm --create /dev/md5 --level=5 --raid- devices=6 /dev/sdz1 /dev/sdr1 /dev/sdap1 /dev/sdah1 /dev/sdj1 /dev/sdb1 mdadm --create /dev/md6 --level=5 --raid- devices=6 /dev/sdad1 /dev/sdv1 /dev/sdat1 /dev/sdal1 /dev/sdn1 /dev/sdf1 mdadm --create /dev/md7 --level=5 --raid-devices=5 /dev/sdq1 /dev/sdao1 /dev/sdag1 /dev/sdi1 /dev/sda1 mdadm --create /dev/md8 --level=5 --raid-devices=5 /dev/sdu1 /dev/sdas1 /dev/sdak1 /dev/sdm1 /dev/sde1
Sinon il est possible d'avoir un disk de spare pour tous les raids, cf doc :
[1]
mais je n'ai pas eu le temps de tester.
Pour verifier:
cat /proc/mdstat mdadm --query /dev/md1
Pour supprimer:
mdadm /dev/md1 stop mdadm /dev/md1 --remove mdadm --zero-superblock /dev/hdxx1
mkfs -t ext3 /dev/md1 mount /dev/md1 /scratch
Pour les drivers:
telecharger les outils et driver linux:
http://www.sun.com/servers/x64/x4500/downloads.jsp
telecharger: kernel-largesmp-devel-2.6.9-42.0.3.EL.x86_64
Par contre il crée /usr/src/kernels/2.6.9-42.0.3.EL-largesmp-x86_64 au lieu de /usr/src/kernels/2.6.9-42.0.3.ELlargesmp-x86_64
faire donc un:
cp -r /usr/src/kernels/2.6.9-42.0.3.EL-largesmp-x86_64 /usr/src/kernels/2.6.9-42.0.3.ELlargesmp-x86_64
Ensuite:
rpmbuild --rebuild mvSatalinux-3.6.3_2-2.6.9_42.ELsmp_1.src.rpm rpm -e (de tous les rpm: "rpm -qa | grep -i mvsata") rpm -ivh /usr/src/redhat/RPMS/x86_64/mvSatalinux-3.6.3_2-2.6.9_42.0.3.ELlargesmp_1.x86_64.rpm rpm -ivh /usr/src/redhat/RPMS/x86_64/mvSatalinux-debuginfo-3.6.3_2-2.6.9_42.0.3.ELlargesmp_1.x86_64.rpm
verifier:
# modinfo mv_sata filename: /lib/modules/2.6.9-42.0.3.ELlargesmp/kernel/drivers/scsi/mv_sata.ko description: Marvell Serial ATA PCI-X Adapter version: 3.6.3_2 license: BSD alias: pci:v000011ABd00007042sv*sd*bc*sc*i* alias: pci:v000011ABd00006042sv*sd*bc*sc*i* alias: pci:v000011ABd00006041sv*sd*bc*sc*i* alias: pci:v000011ABd00006081sv*sd*bc*sc*i* alias: pci:v000011ABd00005041sv*sd*bc*sc*i* alias: pci:v000011ABd00005040sv*sd*bc*sc*i* alias: pci:v000011ABd00005081sv*sd*bc*sc*i* alias: pci:v000011ABd00005080sv*sd*bc*sc*i* depends: scsi_mod vermagic: 2.6.9-42.0.3.ELlargesmp SMP gcc-3.4 }}}
Test Performance Lecture/ecriture
# more /proc/mdstat
Personalities : [raid5]
md7 : active raid5 sdao1[1] sdag1[2] sdq1[0] sdi1[3]
1953535744 blocks level 5, 64k chunk, algorithm 2 [5/4] [UUUU_]
md5 : active raid5 sdap1[2] sdah1[3] sdz1[0] sdr1[1] sdj1[4] sdb1[5]
2441919680 blocks level 5, 64k chunk, algorithm 2 [6/6] [UUUUUU]
md3 : active raid5 sdaq1[2] sdai1[3] sdaa1[0] sds1[1] sdk1[4]
2441919680 blocks level 5, 64k chunk, algorithm 2 [6/5] [UUUUU_]
md8 : active raid5 sdas1[1] sdak1[2] sdu1[0] sdm1[3] sde1[4]
1953535744 blocks level 5, 64k chunk, algorithm 2 [5/5] [UUUUU]
md6 : active raid5 sdat1[2] sdal1[3] sdad1[0] sdv1[1] sdn1[4] sdf1[5]
2441919680 blocks level 5, 64k chunk, algorithm 2 [6/6] [UUUUUU]
md4 : active raid5 sdau1[2] sdam1[3] sdae1[0] sdw1[1] sdo1[4] sdg1[5]
2441919680 blocks level 5, 64k chunk, algorithm 2 [6/6] [UUUUUU]
md2 : active raid5 sdav1[2] sdan1[3] sdaf1[0] sdx1[1] sdp1[4]
2441919680 blocks level 5, 64k chunk, algorithm 2 [6/5] [UUUUU_]
md1 : active raid5 sdar1[2] sdaj1[3] sdab1[0] sdt1[1] sdl1[4] sdd1[5]
2441919680 blocks level 5, 64k chunk, algorithm 2 [6/6] [UUUUUU]
en MB/s Volumétrie: 19TB utile | md1 md2 md3 md4 md5 md6 md7 md8 MOY TOT (Mb/s) Mb/s/TB Write// 71,22 69,31 68,13 71,26 70,14 69,56 62,56 65,89 68,50 4384,56 230,76 write seq 111,01 103,42 102,24 109,77 112,58 107,02 84,61 89,6 102,53125 read // 99,62 98,75 98,22 99,78 100,93 100,01 85,7 86,69 96,2125 6157,6 324,08 read seq 275,4 254,28 250,69 267,62 274,16 280,52 188,37 197,58 248,5775
Configuration Reseaux avec 2 intefaces bond
[root@node23 ~]# more /etc/modprobe.conf alias eth0 e1000 alias eth1 e1000 alias eth2 e1000 alias eth3 e1000 alias eth4 e1000 alias eth5 e1000 alias eth6 e1000 alias eth7 e1000 install ipw3945 /sbin/modprobe --ignore-install ipw3945 ; sleep 0.5 ; /sbin/ipw3 945d --quiet remove ipw3945 /sbin/ipw3945d --kill ; /sbin/modprobe -r --ignore-remove ipw3945 alias usb-controller ehci-hcd alias usb-controller1 ohci-hcd ####BONDING alias bond0 bonding alias bond1 bonding #options bond0 -o bond0 mode=0 miimon=100 options bond0 mode=0 miimon=100 max_bonds=2 options bond1 -o bond1 mode=0 miimon=100 ####END BONDING #Added mv_sata binary driver rpm installation alias scsi_hostadapter mv_sata alias sata_mv off [root@node23 ~]#
[root@node23 ~]# more /etc/sysconfig/network-scripts/ifcfg-* :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-bond0 :::::::::::::: ONBOOT=yes DEVICE=bond0 TYPE=Ethernet BOOTPROTO=static IPADDR=192.54.208.82 NETMASK=255.255.255.0 BROADCAST=192.54.208.255 :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-bond1 :::::::::::::: ONBOOT=yes DEVICE=bond1 TYPE=Ethernet BOOTPROTO=static IPADDR=192.54.208.101 NETMASK=255.255.255.0 BROADCAST=192.54.208.255 :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth0 :::::::::::::: ONBOOT=yes DEVICE=eth0 TYPE=Ethernet BOOTPROTO=none MASTER=bond0 SLAVE=yes :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth1 :::::::::::::: ONBOOT=yes DEVICE=eth1 TYPE=Ethernet BOOTPROTO=none MASTER=bond0 SLAVE=yes :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth2 :::::::::::::: ONBOOT=yes DEVICE=eth2 TYPE=Ethernet BOOTPROTO=none MASTER=bond0 SLAVE=yes :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth3 :::::::::::::: ONBOOT=yes DEVICE=eth3 TYPE=Ethernet BOOTPROTO=none MASTER=bond0 SLAVE=yes :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth4 :::::::::::::: ONBOOT=yes DEVICE=eth4 TYPE=Ethernet BOOTPROTO=none MASTER=bond1 SLAVE=yes :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth5 :::::::::::::: ONBOOT=yes DEVICE=eth5 TYPE=Ethernet BOOTPROTO=none MASTER=bond1 SLAVE=yes :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth6 :::::::::::::: ONBOOT=yes DEVICE=eth6 TYPE=Ethernet BOOTPROTO=none MASTER=bond1 SLAVE=yes :::::::::::::: /etc/sysconfig/network-scripts/ifcfg-eth7 :::::::::::::: ONBOOT=yes DEVICE=eth7 TYPE=Ethernet BOOTPROTO=none MASTER=bond1 SLAVE=yes ::::::::::::::
# ifconfig
bond0 Link encap:Ethernet HWaddr 00:14:4F:20:FC:B0
inet addr:192.54.208.82 Bcast:192.54.208.255 Mask:255.255.255.0
inet6 addr: fe80::200:ff:fe00:0/64 Scope:Link
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:96129841 errors:2 dropped:0 overruns:0 frame:1
TX packets:86702743 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:144510750072 (134.5 GiB) TX bytes:7460167641 (6.9 GiB)
bond1 Link encap:Ethernet HWaddr 00:15:17:2A:09:A6
inet addr:192.54.208.101 Bcast:192.54.208.255 Mask:255.255.255.0
inet6 addr: fe80::200:ff:fe00:0/64 Scope:Link
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:934011 errors:0 dropped:0 overruns:0 frame:0
TX packets:33 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:62926730 (60.0 MiB) TX bytes:2572 (2.5 KiB)
eth0 Link encap:Ethernet HWaddr 00:14:4F:20:FC:B0
inet6 addr: fe80::214:4fff:fe20:fcb0/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:73871160 errors:2 dropped:0 overruns:0 frame:1
TX packets:21675694 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:110757099435 (103.1 GiB) TX bytes:1865279045 (1.7 GiB)
Base address:0xac00 Memory:fd2e0000-fd300000
eth1 Link encap:Ethernet HWaddr 00:14:4F:20:FC:B0
inet6 addr: fe80::214:4fff:fe20:fcb0/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:22109357 errors:0 dropped:0 overruns:0 frame:0
TX packets:21675683 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:33554660288 (31.2 GiB) TX bytes:1864208904 (1.7 GiB)
Base address:0xa800 Memory:fd2c0000-fd2e0000
eth2 Link encap:Ethernet HWaddr 00:14:4F:20:FC:B0
inet6 addr: fe80::214:4fff:fe20:fcb0/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:55195 errors:0 dropped:0 overruns:0 frame:0
TX packets:21675683 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:68939873 (65.7 MiB) TX bytes:1865275229 (1.7 GiB)
Base address:0xbc00 Memory:fd3e0000-fd400000
eth3 Link encap:Ethernet HWaddr 00:14:4F:20:FC:B0
inet6 addr: fe80::214:4fff:fe20:fcb0/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:94129 errors:0 dropped:0 overruns:0 frame:0
TX packets:21675683 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:130050476 (124.0 MiB) TX bytes:1865404463 (1.7 GiB)
Base address:0xb800 Memory:fd3c0000-fd3e0000
eth4 Link encap:Ethernet HWaddr 00:15:17:2A:09:A6
inet6 addr: fe80::215:17ff:fe2a:9a6/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:10 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:758 (758.0 b)
Base address:0xec00 Memory:fe4e0000-fe500000
eth5 Link encap:Ethernet HWaddr 00:15:17:2A:09:A6
inet6 addr: fe80::215:17ff:fe2a:9a6/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:5 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:390 (390.0 b) TX bytes:714 (714.0 b)
Base address:0xe800 Memory:fe4c0000-fe4e0000
eth6 Link encap:Ethernet HWaddr 00:15:17:2A:09:A6
inet6 addr: fe80::215:17ff:fe2a:9a6/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:1 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:66 (66.0 b) TX bytes:628 (628.0 b)
Base address:0xfc00 Memory:fe7e0000-fe800000
eth7 Link encap:Ethernet HWaddr 00:15:17:2A:09:A6
inet6 addr: fe80::215:17ff:fe2a:9a6/64 Scope:Link
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:934005 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:62926274 (60.0 MiB) TX bytes:472 (472.0 b)
Base address:0xf800 Memory:fe7c0000-fe7e0000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:294 errors:0 dropped:0 overruns:0 frame:0
TX packets:294 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:46053 (44.9 KiB) TX bytes:46053 (44.9 KiB)
Exemple de connection avec iperf (4 client pour chacune des interfaces)
tcp 0 0 *:20008 *:* LISTEN tcp 0 0 *:20009 *:* LISTEN tcp 0 0 node23.datagrid.cea.f:20008 wn048.datagrid.cea.fr:51269 ESTABLISHED tcp 0 0 node27.datagrid.cea.f:20009 node02.datagrid.cea.f:39957 ESTABLISHED tcp 0 0 node23.datagrid.cea.f:20008 wn004.datagrid.cea.fr:35417 ESTABLISHED tcp 0 0 node23.datagrid.cea.f:20008 node01.datagrid.cea.f:38544 ESTABLISHED tcp 0 0 node27.datagrid.cea.f:20009 wn049.datagrid.cea.fr:34206 ESTABLISHED tcp 0 0 node23.datagrid.cea.f:20008 wn005.datagrid.cea.fr:35380 ESTABLISHED tcp 0 0 node27.datagrid.cea.f:20009 wn050.datagrid.cea.fr:34567 ESTABLISHED tcp 0 0 node27.datagrid.cea.f:20009 wn006.datagrid.cea.fr:42137 ESTABLISHED
Exemple de configuration pour le SE DPM
[root@node24 root]# dpm-qryconf
POOL CMS_SC DEFSIZE 200.00M GC_START_THRESH 0 GC_STOP_THRESH 0 DEF_LIFETIME 7.0d DEFPINTIME 2.0h
MAX_LIFETIME 1.0m MAXPINTIME 12.0h FSS_POLICY maxfreespace GC_POLICY lru RS_POLICY fifo GIDS 0 S_TYPE -
MIG_POLICY none RET_POLICY R
CAPACITY 23.51T FREE 22.27T ( 94.7%)
node25.datagrid.cea.fr /pool_node25 CAPACITY 4.48T FREE 4.39T ( 98.1%)
node26.datagrid.cea.fr /pool_node26 CAPACITY 233.71G FREE 216.23G ( 92.5%)
node26.datagrid.cea.fr /pool_node26_2 CAPACITY 1.79T FREE 1.69T ( 94.5%)
node23.datagrid.cea.fr /dteam1 CAPACITY 2.24T FREE 2.09T ( 93.2%)
node23.datagrid.cea.fr /dteam2 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node23.datagrid.cea.fr /dteam3 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node23.datagrid.cea.fr /dteam7 CAPACITY 1.79T FREE 1.68T ( 93.8%)
node27.datagrid.cea.fr /dteam4 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node27.datagrid.cea.fr /dteam5 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node27.datagrid.cea.fr /dteam6 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node27.datagrid.cea.fr /dteam8 CAPACITY 1.79T FREE 1.68T ( 93.8%)
Configuration Reseaux avec 1 intefaces bond
# more /etc/modprobe.conf alias eth0 e1000 alias eth1 e1000 alias eth2 e1000 alias eth3 e1000 alias eth4 e1000 alias eth5 e1000 alias eth6 e1000 alias eth7 e1000 options e1000 InterruptThrottleRate=3000 install ipw3945 /sbin/modprobe --ignore-install ipw3945 ; sleep 0.5 ; /sbin/ipw3 945d --quiet remove ipw3945 /sbin/ipw3945d --kill ; /sbin/modprobe -r --ignore-remove ipw3945 alias usb-controller ehci-hcd alias usb-controller1 ohci-hcd ####BONDING alias bond0 bonding options bond0 mode=0 miimon=100 ####END BONDING #Added mv_sata binary driver rpm installation alias scsi_hostadapter mv_sata alias sata_mv off
recharger les modules, redemarrer le reseaux, et verifier que tout est OK:
# more /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v2.6.3 (June 8, 2005) Bonding Mode: load balancing (round-robin) MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: eth0 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:14:4f:20:fc:b0 Slave Interface: eth1 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:14:4f:20:fc:b1 Slave Interface: eth2 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:14:4f:20:fc:b2 Slave Interface: eth3 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:14:4f:20:fc:b3 Slave Interface: eth4 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:15:17:2a:09:a6 Slave Interface: eth5 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:15:17:2a:09:a7 Slave Interface: eth6 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:15:17:2a:07:8c Slave Interface: eth7 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:15:17:2a:07:8d
Probleme sur les cartes reseaux supplémentaires:
Oct 9 16:40:36 node23 kernel: e1000: eth4: e1000_clean_tx_irq: Detected Tx Unit Hang Oct 9 16:40:36 node23 kernel: Tx Queue <0> Oct 9 16:40:36 node23 kernel: TDH <2> Oct 9 16:40:36 node23 kernel: TDT <2> Oct 9 16:40:36 node23 kernel: next_to_use <2> Oct 9 16:40:36 node23 kernel: next_to_clean <0> Oct 9 16:40:36 node23 kernel: buffer_info[next_to_clean] Oct 9 16:40:36 node23 kernel: time_stamp <1144b73ba> Oct 9 16:40:36 node23 kernel: next_to_watch <0> Oct 9 16:40:36 node23 kernel: jiffies <1144b7a09> Oct 9 16:40:36 node23 kernel: next_to_watch.status <0> Oct 9 16:40:38 node23 kernel: e1000: eth5: e1000_clean_tx_irq: Detected Tx Unit Hang Oct 9 16:40:38 node23 kernel: Tx Queue <0> Oct 9 16:40:38 node23 kernel: TDH <1> Oct 9 16:40:38 node23 kernel: TDT <1> Oct 9 16:40:38 node23 kernel: next_to_use <1> Oct 9 16:40:38 node23 kernel: next_to_clean <0> Oct 9 16:40:38 node23 kernel: buffer_info[next_to_clean] Oct 9 16:40:38 node23 kernel: time_stamp <1144b77fa> Oct 9 16:40:38 node23 kernel: next_to_watch <0> Oct 9 16:40:38 node23 kernel: jiffies <1144b817b> Oct 9 16:40:38 node23 kernel: next_to_watch.status <0>
on n'avait pas le bon driver e1000, voir paragraphe suivant pour loader le bon driver
driver carte réseaux
Pour voir le driver adapté aux cartes:
[root@node23 ~]# lspci | tail -4 0d:01.0 Ethernet controller: Intel Corporation 82546GB Gigabit Ethernet Controller (rev 03) 0d:01.1 Ethernet controller: Intel Corporation 82546GB Gigabit Ethernet Controller (rev 03) 0e:01.0 Ethernet controller: Intel Corporation 82546GB Gigabit Ethernet Controller (rev 03) 0e:01.1 Ethernet controller: Intel Corporation 82546GB Gigabit Ethernet Controller (rev 03) [root@node23 ~]#
telecharger le bon driver puis l'installer:
# rpmbuild -tb e1000-7.6.9.tar.gz # rpm -ivh /usr/src/redhat/RPMS/x86_64/e1000-7.6.9-1.x86_64.rpm Preparing... ########################################### [100%] 1:e1000 ########################################### [100%] original pci.ids saved in /usr/local/share/e1000 original pcitable saved in /usr/local/share/e1000 [root@node23 BONDING]#
Dans le README, il preconnise de loader le module avec l'option interruptThrottleRate=3000:
tout recharger correctement:
ifconfig bond0 down; ifconfig bond1 down; rmmod e1000; modprobe e1000 InterruptThrottleRate=3000,3000,3000,3000,3000,3000,3000,3000 ; rmmod bond0 ; rmmod bond1; modprobe bonding -o bond0 mode=0 miimon=100; modprobe bonding -o bond1 -o bond1 mode=0 miimon=100; /etc/init.d/network restart
et modifier le fichier modprobe:
# more /etc/modprobe.conf alias eth0 e1000 alias eth1 e1000 alias eth2 e1000 alias eth3 e1000 alias eth4 e1000 alias eth5 e1000 alias eth6 e1000 alias eth7 e1000 options e1000 InterruptThrottleRate=3000 install ipw3945 /sbin/modprobe --ignore-install ipw3945 ; sleep 0.5 ; /sbin/ipw3945d --quiet remove ipw3945 /sbin/ipw3945d --kill ; /sbin/modprobe -r --ignore-remove ipw3945 alias usb-controller ehci-hcd alias usb-controller1 ohci-hcd ####BONDING alias bond0 bonding alias bond1 bonding options bond0 mode=0 miimon=100 max_bonds=2 options bond1 -o bond1 mode=0 miimon=100 ####END BONDING #Added mv_sata binary driver rpm installation alias scsi_hostadapter mv_sata alias sata_mv off
Test iperf
1) 1 interface bond0 (eth0, eth1, eth2, eth3): ~ 2,7 Gb/s
[ 4] 10.0-20.0 sec 557 MBytes 467 Mbits/sec [ 5] 10.0-20.0 sec 1.10 GBytes 941 Mbits/sec [ 6] 10.0-20.0 sec 976 MBytes 819 Mbits/sec [ 7] 10.0-20.0 sec 567 MBytes 476 Mbits/sec [ 4] 20.0-30.0 sec 564 MBytes 473 Mbits/sec [ 5] 20.0-30.0 sec 1.10 GBytes 941 Mbits/sec [ 6] 20.0-30.0 sec 969 MBytes 813 Mbits/sec [ 7] 20.0-30.0 sec 558 MBytes 468 Mbits/sec [ 4] 30.0-40.0 sec 561 MBytes 470 Mbits/sec [ 5] 30.0-40.0 sec 1.10 GBytes 941 Mbits/sec [ 6] 30.0-40.0 sec 986 MBytes 827 Mbits/sec [ 7] 30.0-40.0 sec 550 MBytes 461 Mbits/sec
2) 2 interfaces : bond0 (eth0, eth1) et bond1 (eth2,eth3): ~900 Mb/s !!
netstat -a | grep 200 tcp 0 0 *:20008 *:* LISTEN tcp 0 0 *:20010 *:* LISTEN tcp 0 0 node27.datagrid.cea.f:20010 wn049.datagrid.cea.fr:41057 ESTABLISHED tcp 0 0 node27.datagrid.cea.f:20010 wn005.datagrid.cea.fr:44065 ESTABLISHED tcp 0 0 node23.datagrid.cea.f:20008 node01.datagrid.cea.f:34342 ESTABLISHED tcp 0 0 node23.datagrid.cea.f:20008 wn048.datagrid.cea.fr:34032 ESTABLISHED
sur node 23:
[ 4] 20.0-25.0 sec 146 MBytes 244 Mbits/sec [ 5] 20.0-25.0 sec 149 MBytes 251 Mbits/sec [ 4] 25.0-30.0 sec 143 MBytes 240 Mbits/sec [ 5] 25.0-30.0 sec 160 MBytes 268 Mbits/sec [ 4] 30.0-35.0 sec 117 MBytes 196 Mbits/sec [ 5] 30.0-35.0 sec 149 MBytes 250 Mbits/sec
sur node27:
[ 4] 20.0-25.0 sec 101 MBytes 170 Mbits/sec [ 5] 20.0-25.0 sec 164 MBytes 275 Mbits/sec [ 4] 25.0-30.0 sec 108 MBytes 181 Mbits/sec [ 5] 25.0-30.0 sec 180 MBytes 303 Mbits/sec [ 4] 30.0-35.0 sec 102 MBytes 172 Mbits/sec [ 5] 30.0-35.0 sec 162 MBytes 272 Mbits/sec
3)interfaces : bond0 (eth0, eth1, eth2,eth3) et bond1 (eth4, eth5, eth6,eth7): ~3,8Gb/s
sur node27:
[ 4] 20.0-30.0 sec 337 MBytes 283 Mbits/sec [ 5] 20.0-30.0 sec 393 MBytes 329 Mbits/sec [ 6] 20.0-30.0 sec 425 MBytes 357 Mbits/sec [ 7] 20.0-30.0 sec 758 MBytes 636 Mbits/sec
sur node23:
[ 4] 20.0-30.0 sec 727 MBytes 610 Mbits/sec [ 5] 20.0-30.0 sec 1.10 GBytes 941 Mbits/sec [ 6] 20.0-30.0 sec 360 MBytes 302 Mbits/sec [ 7] 20.0-30.0 sec 359 MBytes 301 Mbits/sec
4) 1 interface bond0 (eth0, eth1, eth2, eth3, eth4, eth5, eth6, eth7): ~5Gb/s
http://lcg.in2p3.fr/wiki/images/Node23_datagrid_cea_fr_rrd_NUMKBREADAVG_d.gif
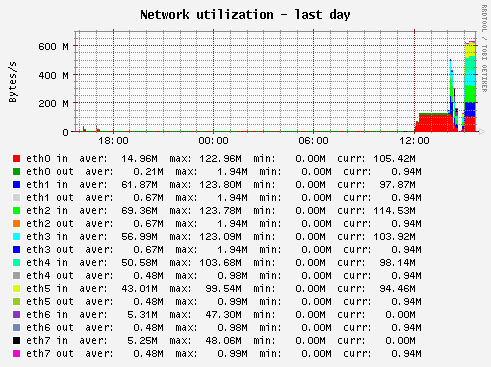{kind=link}
[ 4] 10.0-20.0 sec 841 MBytes 705 Mbits/sec [ 5] 10.0-20.0 sec 1001 MBytes 840 Mbits/sec [ 6] 10.0-20.0 sec 671 MBytes 563 Mbits/sec [ 7] 10.0-20.0 sec 581 MBytes 487 Mbits/sec [ 8] 10.0-20.0 sec 431 MBytes 362 Mbits/sec [ 9] 10.0-20.0 sec 535 MBytes 449 Mbits/sec [ 10] 10.0-20.0 sec 986 MBytes 827 Mbits/sec [ 11] 10.0-20.0 sec 878 MBytes 736 Mbits/sec [ 4] 20.0-30.0 sec 903 MBytes 758 Mbits/sec [ 5] 20.0-30.0 sec 1.04 GBytes 894 Mbits/sec [ 6] 20.0-30.0 sec 263 MBytes 221 Mbits/sec [ 7] 20.0-30.0 sec 169 MBytes 142 Mbits/sec [ 8] 20.0-30.0 sec 731 MBytes 614 Mbits/sec [ 9] 20.0-30.0 sec 916 MBytes 769 Mbits/sec [ 10] 20.0-30.0 sec 922 MBytes 774 Mbits/sec [ 11] 20.0-30.0 sec 395 MBytes 332 Mbits/sec
Test Performance DISK+NETWORK avec DPM
[root@node24 root]# dpm-qryconf
POOL CMS_SC DEFSIZE 200.00M GC_START_THRESH 0 GC_STOP_THRESH 0 DEF_LIFETIME 7.0d DEFPINTIME 2.0h
MAX_LIFETIME 1.0m MAXPINTIME 12.0h FSS_POLICY maxfreespace GC_POLICY lru RS_POLICY fifo GIDS 0 S_TYPE -
MIG_POLICY none RET_POLICY R
CAPACITY 17.01T FREE 15.98T ( 93.9%)
node23.datagrid.cea.fr /dteam1 CAPACITY 2.24T FREE 2.09T ( 93.2%)
node23.datagrid.cea.fr /dteam2 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node23.datagrid.cea.fr /dteam3 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node23.datagrid.cea.fr /dteam7 CAPACITY 1.79T FREE 1.68T ( 93.8%)
node23.datagrid.cea.fr /dteam4 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node23.datagrid.cea.fr /dteam5 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node23.datagrid.cea.fr /dteam6 CAPACITY 2.24T FREE 2.11T ( 94.1%)
node23.datagrid.cea.fr /dteam8 CAPACITY 1.79T FREE 1.68T ( 93.8%)
sur l'UI:
[cleroy@node02 2_IPbonding]$ time ./transfert_concurrent_client_node24.py globus-url-copy file:/home/cleroy/DTEAM_2004/4_Tt2t1/ATLAS_DATA gsiftp://node24.datagrid.cea.fr/dpm/datagrid.cea.fr/home/dteam/dapnia/cleroy/TO_BE_REMOVED/ ATLAS_DATA_Trf00001 ... .... real 2m13.017s user 1m4.270s sys 0m48.790s
Sur le SE disk:
[root@node23 ~]# ll /dteam*/dteam/2007-10-10 /dteam1/dteam/2007-10-10: total 1441096 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA2_Trf00001.4189.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA3_Trf00000.4181.0 /dteam2/dteam/2007-10-10: total 1441104 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:37 ATLAS_DATA_Trf00000.4182.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:37 ATLAS_DATA_Trf00001.4174.0 -rw-r--r-- 1 root root 5 Oct 10 17:27 essai /dteam3/dteam/2007-10-10: total 1441096 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA4_Trf00001.4175.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:37 ATLAS_DATA8_Trf00001.4183.0 /dteam4/dteam/2007-10-10: total 1441096 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:37 ATLAS_DATA7_Trf00001.4184.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA8_Trf00000.4176.0 /dteam5/dteam/2007-10-10: total 1441096 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA2_Trf00000.4177.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:37 ATLAS_DATA7_Trf00000.4185.0 /dteam6/dteam/2007-10-10: total 1441096 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA5_Trf00001.4178.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:37 ATLAS_DATA6_Trf00000.4188.0 /dteam7/dteam/2007-10-10: total 1441096 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA3_Trf00001.4186.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA6_Trf00001.4180.0 /dteam8/dteam/2007-10-10: total 1441096 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA4_Trf00000.4179.0 -rw-rw---- 1 dpmmgr dpmmgr 737108530 Oct 10 17:38 ATLAS_DATA5_Trf00000.4187.0
16 fichiers en paralleles de 737 MB:
11792 MB en 133 s = 88 MB/s = 709 Mb/s
autre test: (16 * 20 = 320 )fichiers de 737MB : 235840 MB en 30m29.512s : 128 MB/s : 1024 Mb/s
DPM et XROOTD
Ce document décrit la procédure utilisée à l'IPNO pour installer xrootd sur un serveur DPM. La procédure d'installation doit être effectuée sur chaque server (head node et disk servers). A l'IPNO l'installation a eu lieu sur un unique serveur à la fois head node et disk server.
La documentation utile
Configuring 'xroot' Protocol on DPM (Andreas Peters) BR https://twiki.cern.ch/twiki/bin/view/LCG/DpmXrootAccess
How to Install and Debug Xrootd on a DPM Storage Element (Jean-Michel Barbet) BR http://alien.cern.ch/twiki/bin/view/AliEn/HowToInstallXrootdAndDPM
LCG-France T2-T3 Technical meeting : DPM/xrootd introduction (Jean-Michel Barbet)BR http://indico.in2p3.fr/conferenceDisplay.py?confId=821
Xrootd Tutorial (Artem Trunov) BR http://indico.cern.ch/materialDisplay.py?contribId=8&sessionId=0&materialId=slides&confId=a058483
Firewall: ports à ouvrir
* Sur le xrootd Manager (DPM head node) : 1094 * Sur les xrootd servers (disk servers) : 1095 * Si le xrootd manager est aussi disk server : 1095 (sur le manager en plus de 1094)
Installation Configuration en utilisant les scripts fournis par ALICE
SPMA
Editer /etc/spma.conf :
* userpkgs = yes * userprio = yes
Non-YAIM configuration
{{{
* # wget http://project-arda-dev.web.cern.ch/project-arda-dev/xrootd/tarballs/installbox/dpm-config.tgz * # tar zxf dpm-config.tgz * # chmod u+x ./conf.xrootd
}}}
Il faut commenter l'appel à la fonction requires dans config_DPM_xrootd et définir la variable YAIM_LOG dans conf.xrootd, sinon il y a des messages d'erreur au lancement de conf.xrootd .
{{{
* # cp config_DPM_xrootd config_DPM_xrootd.orig * # cp conf.xrootd conf.xrootd.orig * # vi config_DPM_xrootd ---> commenter l'appel à requires * # vi conf.xrootd ---> définir YAIM_LOG
* # diff config_DPM_xrootd config_DPM_xrootd.orig * 2c2 * < #requires $1 INSTALL_ROOT * --- * > requires $1 INSTALL_ROOT
* # diff conf.xrootd conf.xrootd.orig * 4d3 * < YAIM_LOG=/tmp/yaim.log
Alice utilise l'authentification TokenAuthZ. GSI n'est pas encore supportée. Il faut donc éditer le fichier
/opt/lcg/etc/xrootd/authz.cf (ce fichier ne sera pas utile avec GSI).
* # vi /opt/lcg/etc/xrootd/authz.cf : * changer /usr/local/xroot en /opt/lcg et * EXPORT PATH:/ en EXPORT PATH:/dpm/in2p3.fr/home/alice/
Editer les scripts de lancement pour changer XRDLOCATION="/usr/local/xroot" en XRDLOCATION="/opt/lcg".
Les fichiers à éditer sont : /etc/init.d/dpm-xrd /etc/init.d/dpm-olb /etc/init.d/dpm-manager-xrd /etc/init.d/dpm-manager-olb /etc/init.d/xrdapmon
Les scripts de démarrage regénèrent à chaque lancement le fichier /opt/lcg/etc/xrd.dpm.cf utilisé par les daemons. Ce fichier est créé à partir du fichier /etc/xrd.dpm.config (ou /etc/xrd.dpm.config.gsi si avec GSI). C'est donc dans /etc/sysconfig/dpm-xrd qu'il faut modifier la config xrootd si besoin est, avant de relancer les daemons.
Modifier /etc/sysconfig/dpm-xrd comme indiqué ci-dessous :
* # cp /etc/sysconfig/dpm-xrd.example /etc/sysconfig/dpm-xrd * # vi /etc/sysconfig/dpm-xrd * ... * # set the redirector host * MANAGERHOST="ipnsedpm.in2p3.fr" * export DPM_HOST=$MANAGERHOST * export DPNS_HOST=$MANAGERHOST * ... * ############################################################################# * # default authentication is with GSI authentication * #XRDCONFIG="xrd.dpm.config.gsi" * # if you want GSI authentication disabled set * XRDCONFIG="xrd.dpm.config" * ... * #XRDOFS="Ofs" * # the ALICE Ofs plugin * XRDOFS="TokenAuthzOfs
* # vi /etc/shift.conf * Ajouter (à faire normalement via Quattor): * DPM PROTOCOLS rfio gsiftp xroot
* Lancer la config :
* # ./conf.xrootd
* # more /tmp/yaim.log * # service dpm restart * # service dpnsdaemon restart (peut-etre pas necessaire)
Les process qui tournent
Sur le manager :
{{{
* dpmmgr 2816 1 0 Apr28 ? 00:00:00 /opt/lcg/bin/dpm-manager-olbd -d -b -n manager -c /opt/lcg/etc/xrd.dpm.cf -l /var/log/xroot//olblog * dpmmgr 3004 1 0 Apr28 ? 00:00:00 /opt/lcg/bin/dpm-manager-xrootd-d -b -n manager -c /opt/lcg/etc/xrd.dpm.cf -l /var/log/xroot//xrdlog
}}}
Sur les servers xrootd :
* dpmmgr 2726 1 0 Apr28 ? 00:00:00 /opt/lcg/bin/dpm-olbd -d -b -n server -c /opt/lcg/etc/xrd.dpm.cf -l /var/log/xroot//olblog * dpmmgr 2911 1 0 Apr28 ? 00:00:03 /opt/lcg/bin/dpm-xrootd -d -b -n server -c /opt/lcg/etc/xrd.dpm.cf -l /var/log/xroot//xrdlog
Test
* xrdcp /etc/hosts root://ipnsedpm.in2p3.fr://dpm/in2p3.fr/home/alice/test_ok.txt -v * xrdcp root://ipnsedpm.in2p3.fr://dpm/in2p3.fr/home/alice/test_ok.txt /tmp/xrd_copied_file -v
Utiliser l'option '-d 1' par exemple pour un mode un peu plus verbeux.
Les fichiers peuvent être effacer par rfrm :
* # rfrm /dpm/in2p3.fr/home/alice/test_ok.txt
En principe ça ne devrait pas marcher car il faut être authetifié par TokenAuthZ pour pouvoir faire des delete.
Divers
Pour arrêter / démarrer les services
* service dpm-xrd restart * service dpm-olb restart * service dpm-manager-xrd restart * service dpm-manager-olb restart
L'authentification
xrootd ne supporte pas encore d'authentification GSI mais l'authentification TokenAuthZ. Le fichier d'authentification est le suivant :
* # cat /opt/lcg/etc/xrootd/authz.cf * KEY VO:* PRIVKEY:/opt/lcg/etc/xrootd/pvkey.pem PUBKEY:/opt/lcg/etc/xrootd/pkey.pem * EXPORT PATH:/dpm/in2p3.fr/home/alice/ VO:* ACCESS:ALLOW CERT:* * RULE PATH:/ AUTHZ:delete| NOAUTHZ:read|write|write-once| VO:* CERT:*
La dernière ligne signifie que tout le monde peut lire et écrire via xrootd, mais qu'il faut une authentification via TokenAuthZ pour pouvoir supprimer les fichiers.
Installation Configuration en utilisant Quattor
installation RPM
RPM disponible: http://project-arda-dev.web.cern.ch/project-arda-dev/alice/xrootd-dpm/
Pour installer les bons RPM, il faut cette variable :
variable SEDPM_XROOTD_SERVER = true;
pour la liste de RPMs, voir les templates:
cfg/grid/glite-3.1/glite/se_dpm/rpms/ « arch »/xrootd_*.tpl
configuration
Actuellement configuration à la main, voir :
http://lcg2.in2p3.fr/wiki/index.php/User_talk:LEROY#Non-YAIM_configuration
+ lien à créer:
ln -s /opt/lcg/lib/libXrdSec.so /opt/lcg/lib64/libXrdSec.so
Pour configuration via quattor: Modification des templates à revoir (problemes du component):
{{{ Sending cfg/clusters/dapnia-glite-3.1/lcg/source/pro_se_dpm_config.tpl
Sending cfg/clusters/dapnia-glite-3.1/profiles/profile_node11.tpl
Sending cfg/grid/glite-3.1/components/dpmlfc/schema.tpl
Sending cfg/grid/glite-3.1/glite/se_dpm/config.tpl
Adding cfg/grid/glite-3.1/glite/se_dpm/disk/xrootd.tpl
Sending cfg/grid/glite-3.1/glite/se_dpm/rpms/config.tpl
Adding cfg/grid/glite-3.1/glite/se_dpm/rpms/i386/xrootd_disk.tpl
Adding cfg/grid/glite-3.1/glite/se_dpm/rpms/i386/xrootd_head.tpl
Adding cfg/grid/glite-3.1/glite/se_dpm/rpms/x86_64/xrootd_disk.tpl
Adding cfg/grid/glite-3.1/glite/se_dpm/rpms/x86_64/xrootd_head.tpl
Adding cfg/grid/glite-3.1/glite/se_dpm/server/xrootd.tpl
Sending cfg/grid/glite-3.1/glite/se_dpm/service.tpl
Sending cfg/grid/glite-3.1/machine-types/se_dpm.tpl
Sending cfg/grid/glite-3.1/repository/config/glite.tpl }}}
Conclusion
Si on cumule test lecture/écriture et test iperf (avec 1 interface bond0 qui agrège les 8 Ethernet) on arrive à sortir les 230Mb/s et par TB.
Necessite de bien maîtriser le raid logiciel et de le monitorer
Existence des drivers pour quelques versions de Linux